
事件相机应用最新进展
前言
江老师既然已经给定了选题,咱也不要犹豫了,犹豫就会败北,赶快开始准备综述材料和积累与运用吧!
在写作每周的综述报告时,虽然老师没有要求,自己还是要严格对待,至少要包括这些内容:主要看了什么内容,用一句话概括一下。技术应用型论文,侧重介绍方法和实施手段,特别是算法设计上。理论研究型论文,侧重介绍理论推导和关键技巧。
两种论文,都要以能够找出其不足和缺点作为论文阅读的终极目标,当然也不需要按图索骥,慢慢积累,水到自然渠成。可惜分身乏术,不然还能分个身出来复现一下它们的算法和结果,如果能做到那就实在是太厉害了。
2023/10/23 当周进展
本周论文概览
本周一共看了6篇文献,其中4篇都是同一个类型(讲STDP生理学基础的)所以归作一篇文献,另外两篇是事件相机在无人机领域的应用,两篇都是避障,第一篇是动态避障,另一篇是静态避障,两篇都用了YOLO检测模型。
第一篇文献
文献名:基于动态视觉传感器的无人机目标检测与避障
北航学报
解决的问题
无人机在动态和静态两种情况下检测出篮球并实施躲避。
采用的方法
事实上是多传感器融合,如下图:
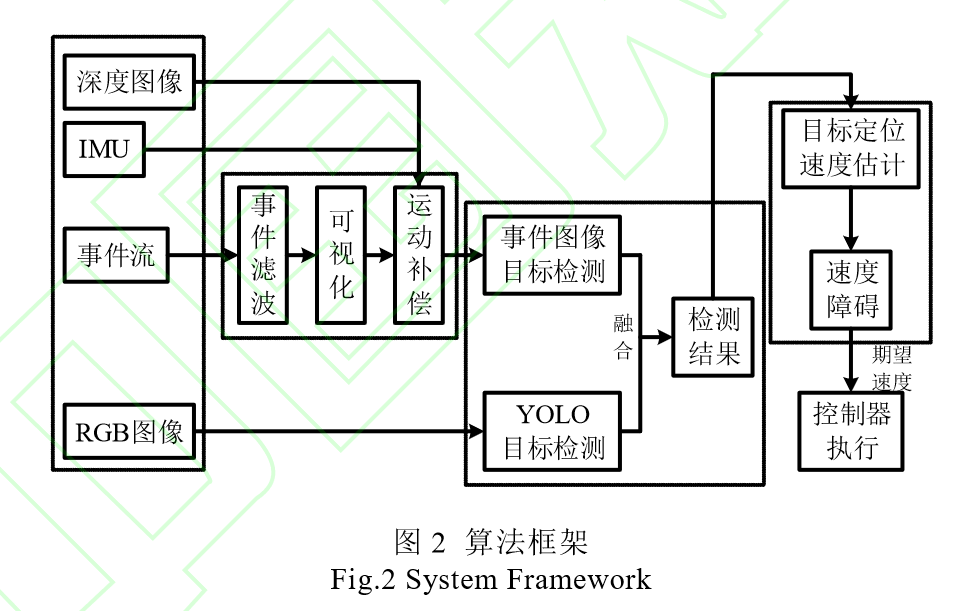
有关事件相机的处理时,采取的方法实际上选用事件图像予以描述,对事件图像按均值滤波和形态学处理,完成图像的分割。其独特的方法在于:将分割后的事件类别各类对时间戳归一化(减去平均时间戳并除以时间间隔),使用一个给定的阈值判定该事件是背景事件B还是目标事件O。
然后将该方法得到的检测结果与使用RGB相机取得并YOLO检测得到的结果按可信度融合(加权平均,动态和静态下的权重不一样,但本文认为YOLO检测结果权重应该更大),同时在时间戳上对齐RGB结果和事件结果,得到在动态和静态情况下都能够检测出篮球的结果。
方法评价
本文的创新点在于事件目标的检测方法设计:使用形态学分割并使用平均时间戳判据,这个计算量较小,在简单的环境中准确度高,这也是本文的缺点:复杂环境下检测结果将不太可靠,复杂环境中过于多的边缘信息会在事件相机上产生较多的事件输出,严重影响事件图像划分结果。
第二篇文献
文献名:Encyclopedia of Computational Neuroscience
Springer New York
文献主要内容
介绍的是计算脑科学,即使用仿生手段在计算机算法中的应用。自下而上地介绍了在SNN领域的一些基本的概念,如从脉冲现象开始,脉冲的定义、脉冲序列的定义、脉冲序列的描述手段(距离、相似度)、脉冲神经元的工作方式(LF、RF模型)、脉冲神经网络的工作手段(前向传播用资格迹、后向传播用STDP),构建起完整的脉冲神经网络基础知识。
2023/10/30 当周进展
第一篇文献
文献名:Dynamic obstacle avoidance for quadrotors with event cameras
Science
解决的问题
无人机在室内和室外条件下,在自身处于较高速运动的情况下,对高动态运动的障碍物进行躲避。本文提出的方法能够在3.5毫秒内作为响应,最高能够应对的相对速度。
采用的方法
一句话概括:本文使用的是自移动补偿的时间曲面动态阈值分割法,得到的目标矩阵框估计使用卡尔曼滤波器输出位置和速度,使用人工势能场方法得到控制信号。
自移动补偿ego-motion compensation
由于相机自身也在高速运动,所以直接得到的位置不是惯性系下的位置信息,对某一时间间隔,得到一个事件流,使用无人机固连的IMU模块输出的角速度信息(使用这一时间间隔内的平均角速度)作为当前无人机运动的角速度,然后将全部事件点根据时间的关系旋转至的位置,得到的补偿事件流按位置生成二维时间曲面,即每个坐标位置的值等于其算术平均时间戳:
文献中为了消除单位的影响,对上式作了一次中心化操作,即时间曲面减去其均值并除以时间间隔得到:
第二步:对中心化后的时间曲面取定阈值分割,文献中取定该阈值为一个与角速度值呈线性关系的函数,即:
阈值分割结果有椒盐噪声,使用形态学滤波器去除噪声,得到分割的二值结果图。
聚类与目标检测
文献使用了DBSCAN聚类法,该方法来自于文献A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise,能够进一步滤除噪声。文献改进了DBSCAN的距离计算方法,重新定义了聚类的代价函数:
式中,是两个聚类点的序号,是三个代价权重。而DBSCAN聚类方法时间成本为,本文特别重视延迟(提出观点与其精准不如快速),在两个地方上进行简化:
- 使用一步预聚类,即使用8连通判据将各个连通的像素点划为一类,并提取出其矩形凸包;
- 上述代价函数不再逐点计算,而是以矩阵凸包间的最小距离作为距离项,以平均速度和平均中心化时间戳作为后面两项,计算其代价,即有:
当两个凸包重叠时,认为第一项为0。
聚类完成仅得到目标实体的像素平面位置信息,不能得到深度信息,不能辅助无人机判断障碍物远近。本文在两种情况下使用了不同的深度估计方法:使用单目深度估计,此时需要先验飞来障碍物的大小,然后使用小孔成像模型计算深度距离。使用双目立体深度估计时,本文进一步修改代价函数,引入两个事件相机分割结果:
式中,分别是上下两个事件相机成像分割结果的中心位置,分别是上下两个分割结果的面积,分别是上下两个分割结果的像素点数。是三个权重,是深度估计的先验权重,是面积和像素点数的权重,是为了将代价函数的值域限制在之间,然后根据估计的深度,可以得到目标的大小和位置,并使用已标定的相机内参反演出世界坐标系下的物体位置。
速度估计与控制
深度估计和位置估计能够得到较为准确的静态坐标信息,本文使用的人工势能场控制方法需要还需要知道物体相对于无人机的速度信息,本文使用了卡尔曼滤波器对位置和速度进行估计。这部分卡尔曼滤波器和控制理论不作重要介绍。
方法评价
本文的方法非常轻量、简洁,但是效果出奇地好(如下表)。
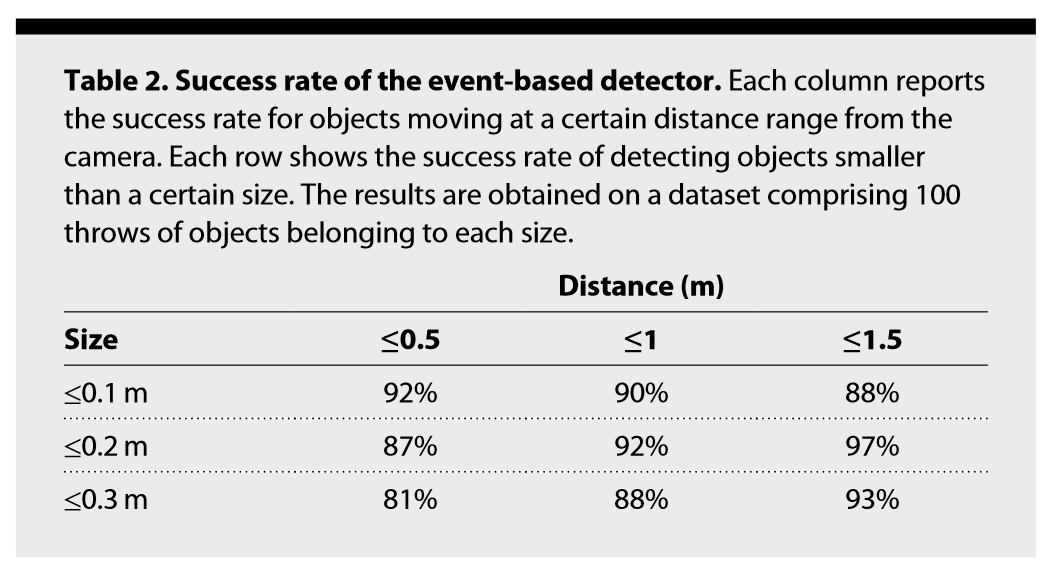
再一次说明,即使是没有使用复杂如神经网络的算法,使用简单的机器学习(聚类)算法也能够得到良好的检测效果。
但是,本文的检测误差始终居高不下,达到了半个机位。
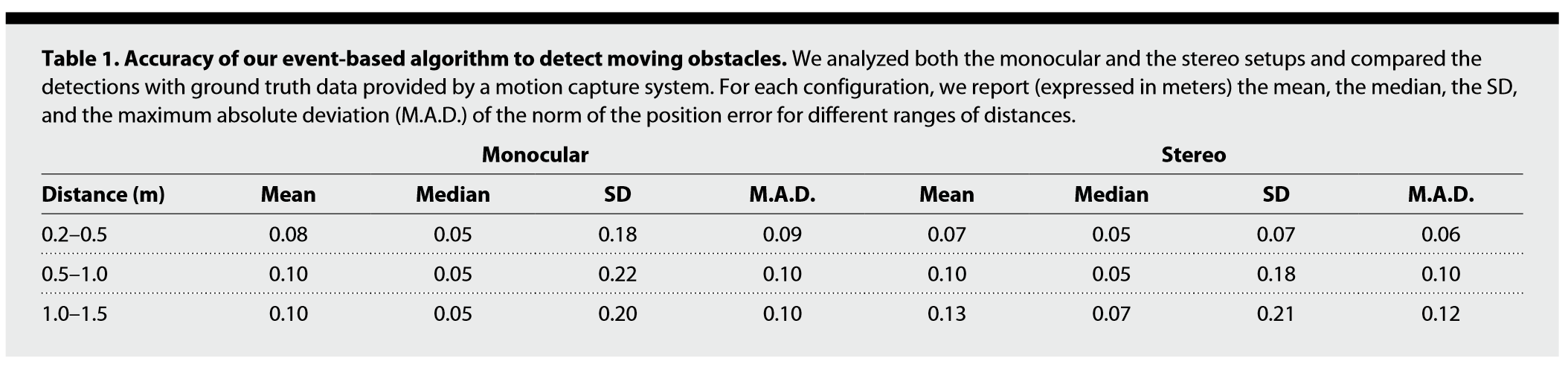
作者自述的原因:事件相机分辨率过于低,当景深较大时,单个像素内足以映射超过无人机自身尺寸的物方空间,因此限制了该无人机对远处飞来物体的躲避能力(不能超过3)。这个原因我赞同,而且是主要的因素,除此以外,作者还认为事件相机尺寸和重量较大,与传统相机相比还并不具有优势。
本文进一步说明,当前的事件相机在空间分辨率上的拮据限制了其在精细测量上的应用,凡是需要控制误差的应用,都不太适应单纯使用事件相机(如另一篇文献Fusing Event-based Camera and Radar for SLAM Using Spiking Neural Networks with Continual STDP Learning便是将微波信号和事件相机相结合,且事件相机仅是起到了高速一个方面的辅助,主要依靠微波雷达,才能完成SLAM任务)。
第三篇文献
文献名:Event-based Navigation for Autonomous Drone Racing with Sparse Gated Recurrent Network
来自于2022年ECC会议
解决的问题
无人机在室内条件下,仅使用事件相机作为视觉传感器,安全穿过数个深色方框。

采用的方法
使用特征提取-回归的模型,判定当前方框的中心并予以轨迹控制。本文使用5层VGG11卷积神经网络作为前馈特征提取器,接受来自事件相机的2D直方图输入,前馈网络的输出作为门控循环单元GRU(Gated Recurrent Unit) 的输入以提取事件直方图之间的语义联系,最后使用两层全连接层作为回归输出385维列向量。值得注意的是,本文中选用的Loss函数是YOLO检测网络的Loss函数,训练过程使用Adam方法优化模型,最后全连接层输出的385维列向量经由YOLO回归方法得到当前检测框中心和框宽高。
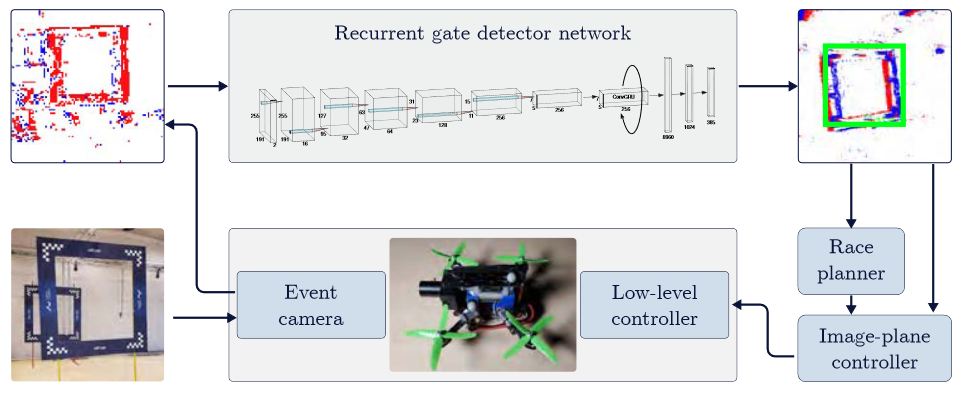
详细方法论
方法实施起来的细节,主要分为框架描述、训练手段和验证手段。
- 训练手段:本文一共准备了两个数据集:仿真和实测,仿真数据集用ESIM仿真器在AirSim环境中搭建四旋翼无人机对象以获取大量仿真数据,自动得到标注结果。在真实环境中使用DAVIS240获取同样的数据集,并人工标注方框位置和大小。使用仿真数据训练CNN网络,然后使用真实数据微调CNN并加入GRU模块,训练整个模块得到最终模型。
- 验证手段:将模型部署在
NVIDIA Jetson TX2嵌入式设备作为传感单元,使用Pixhawk 4 Autopilot board作为控制单元控制姿态和速度。(控制算法略)。 - 框架描述:神经网络总体结构如下图:

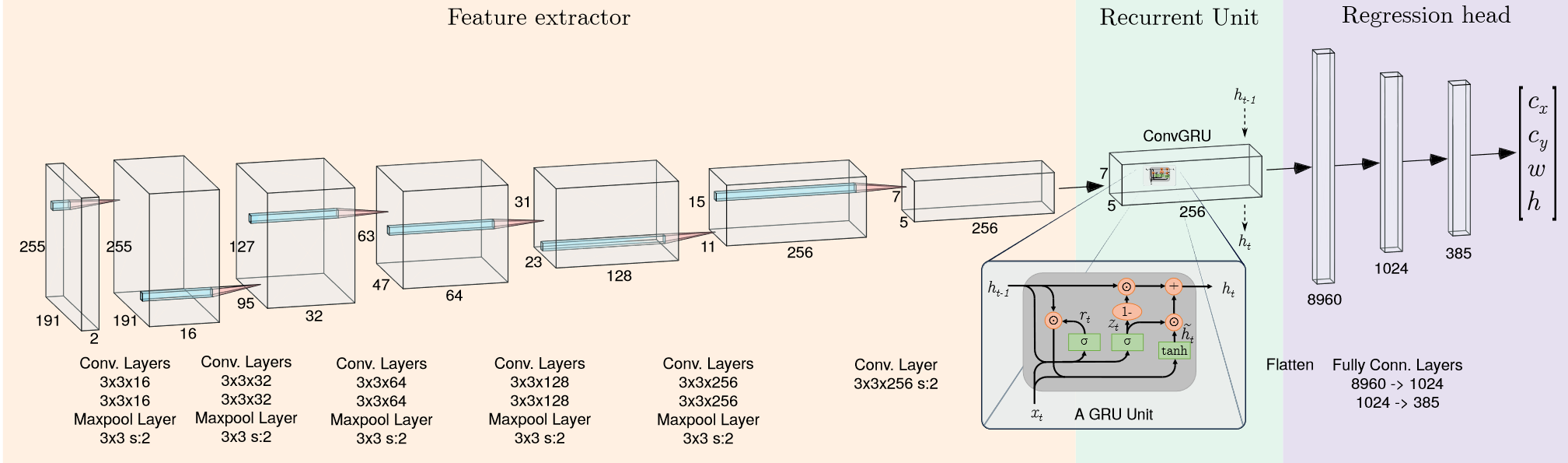
方法评价
本文给我的重要收获有两点:
- 可以使用现成开源的仿真环境平台,获取无人机仿真数据(哪怕不需要事件相机也行,需要事件相机,也只是修改对应对象的接口),不需要重复造轮子;
- 事件点之间的相关性除了事件描述子以外,还可以使用RNN网络提取,而且不需要引入特别深的RNN网络,可以考虑在网络中加入这种子模块增强性能。
本文的方法也有很明显的缺点:无人机运动速度稍慢(以下效果稍好),速度越高效果越差,这还没有体现出事件相机的作用(卷积层太深,嵌入式上处理不过来,实时性就差了),特征提取器有改进空间,我认为可以使用SNN或者SCNN代替这一CNN处理。
近期阅读心得:事件相机受限于极小的空间分辨率,独自承担精准测量是行不通的,必须要借助常规相机或者其他成像手段的辅助(例如声呐、微波雷达)才能得到较为精确的测量结果。
第四篇文献
文献名:EVDodge: Embodied AI For High-Speed Dodging On A Quadrotor Using Event Cameras
解决的问题
本文解决的问题核心还是无人机动态避障,这里是无人机在静态的情况下,对具有先验知识的物体进行单目相机避障。
采取的方法
本文选定的事件描述仍然是时间曲面,即按时间对不同位置的事件进行堆积得到的图像。本文使用了CNN网络和Transformer。
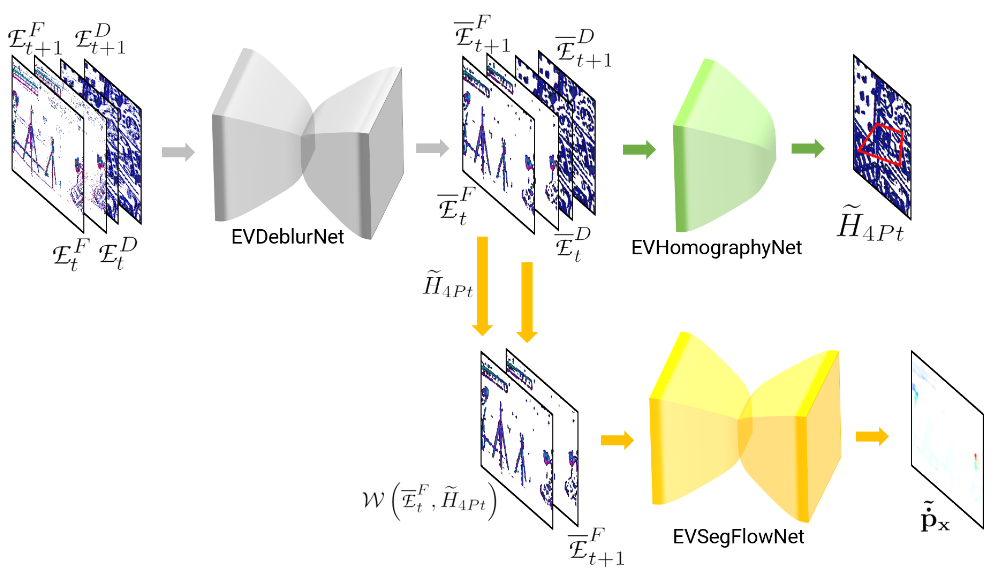
第一层是CNN,被称为EVDeBlurNet,即用于对事件图像降噪,这里降噪的原理仍然是时空密度降噪,即对每一个事件点周边,根据其时间邻域和空间邻域上的相关关系,决定该事件点是否是噪声点,由于采用时间曲面的描述方式,必然会引入延迟和模糊blur,本文定义模糊为:世界坐标系下同一点产生的事件没有在相机平面上对齐(即分散到了不同的点)。因此第一层网络将解决降噪和去模糊两个问题,本文采用了Encoder-Decoder框架(4层卷入4层卷出),其优化函数为:
其中第一项是最大化对比度函数,第二项是对处理前后两幅事件图像的差异性测度惩罚项,保证网络不产生高频噪声(即图像失真)。
第二层被称为EVHomographyNet,用于运动图像配准,即为后续图像分割步骤中,排除背景运动ego-motion带来的干扰。这一层网络使用的是SLT,即Spatial Transformer Network,其目标就是找到一个最优的射影变换矩阵,使得配准前后两幅事件图像的差距达到最小,即:
式中,代表的是函数封装,即有关于前一帧时间曲面经估计得到的射影变换的预测当前时间曲面,而其与当前实际时间曲面的差的期望是需要最优化的函数(理论上可以使用EM框架)。
第三层是EVSegFlowNet,即用于将背景和前景分割开,以找出运动的物体,这里本文使用的是CNN,本文号称使用了“准监督”方式,即对每一个被分割出来认为是前景的像素,再乘以一个概率分布,优化这个概率分布,使分割结果体现为背景尽量保持不动而前景的运动得以凸显。本层网络选用的优化函数是分割后的目标像素之间的差距,同时引入两个正则项以加快收敛并增强稳健性:
式中,第一项的封装函数是将上一时刻经过同质性估计后得到的待分割图像与概率分布进行运算,然后与当前时刻的真实目标分割结果求差。后两项分别是对绝对值范数的惩罚,以增强对散点噪声的稳健性,欧氏范数以加快模型的收敛。
方法评价
本文没有详细展开,仅介绍了方法的框架,其中声呐用于测量高度,而IMU模块用于测量并修正姿态,均是对一前一下两个事件相机能力的补充,再一次说明事件相机不能单独承担作为测量传感器,仅能是作为高频情况下的补充。本文提出的三个神经网络框架也没有什么特别的地方。
2023/10/30 当周进展
第一篇文献
文献名:Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High-Speed Scenarios
IEEE Transactions on Robotics
解决的问题
在保持将IMU信号和事件相机信号融合的前提下,引入常规相机信号,设计一款全新的三信号融合视觉里程计(VIO),使得无人机系统能够得到更精确的定位和追踪结果。
采用的方法
对于事件相机取得的事件流而言,仍然采用事件图像的事件代表方式,以截取事件得到事件图像(本文特别之处在于,事件图像使用的是时空窗的办法,即在固定时间帧率开始采样,当事件数量达到设定的阈值后完成采样并输出,异步产生不同固定时间帧处的事件图像)。然后使用FAST角点检测子检测在事件图像和常规相机图像中的角点,使用KLT追踪子追踪角点特征。值得注意的是,本文使用IMU信号单纯是为事件相机的特征追踪服务的,使用IMU估计得到的姿态变换阵以求出重投影前的事件坐标。公式如下:
式中,左项是重投影后的位置,表示事件相机的成像投影模型,是某个事件在相机平面位置坐标,表示对应事件的深度,即使用相机平面的坐标反演世界坐标下需要补充的先验知识,这里可以使用双目系统得到。
本文的一个亮点在于,常规相机和事件相机构成了双目测量系统,因此当某个特征可以进行三角测量时,作者设计使用两种视觉信号进行三角测量以得到特征的立体标识3D landmark。本文对重投影误差进行最优化以得到前后两个时刻的姿态变换矩阵估计值,完成在该时刻的定位。
方法评价
本文方法将事件相机和传统视觉里程计常用的两个传感器——常规相机和IMU结合起来,能够将平均位置误差控制在0.3%以内,优于单纯使用事件相机与IMU结合或者单纯使用常规相机与IMU结合的方法。本文的数据进一步表明,事件相机单独使用不能在机器视觉领域取得较好的结果,需要进行多传感器融合。
第二篇文献
文献名:AEGNN: Asynchronous Event-based Graph Neural Networks
解决的问题
当前各种使用事件流处理的方式都用到了事件描述(多为时间曲面或者事件图像),均会造成事件本身时空信息的丢失,如何保证在不损失事件信息的前提下,充分使用事件流的异步特性以提高处理速度并完成不同类型的处理任务?
采用的方法
本文使用的方法是图神经网络。在使用图神经网络处理事件数据之前,使用时空密度窗对事件流数据截断,得到某个时间段内的局部事件流。对局部事件流使用次级采样(即每隔个事件点保留一个事件),得到采样事件流。然后从采样事件流中生成事件图graph,生成的方式是按时空距离来决定的。即:每个事件点都看作是一个结点,求取其到其他所有事件点的时空距离,将时空距离小于某个给定阈值的两个事件点之间增加一条边,同时保证全部的边数不多于某一给定阈值。时空距离的求法:
在得到事件图之后,将该图放入图网络中处理并完成给定的视觉任务(论文中示例为汽车检测)。这里本文的一个创新点是,由于生成事件图的时候需要对事件窗内的所有事件点进行距离运算,需要较大的算力,而如果将时空窗改为有重叠的移动,则可以每次仅对新增的事件点进行图卷积,即可得到新的事件图,节省了算力。
方法评价
该方法跳出了传统的网络处理模型或者使用事件描述从而将事件数据使用传统图像处理方法的处理框架,使用图神经网络处理事件数据,有创新的一面。另一方面,该方法对图的生成仍然较为随意,使用时空距离计算图的边,本质上对事件点进行了一次聚类,因此能够在单个目标上或者单类目标上取得较好的结果,而在复杂的环境下得到的效果较差。

图中虚线是该方法结果,实线是另一种图神经网络的方法,可见该方法得到的总体结果较差。





