
23年11月进展
第一篇文献
11月6日
文献名:A Differentiable Recurrent Surface for Asynchronous Event-Based Data
arxiv
解决的问题
本文解决了使用事件流数据中,难以把握手工选定的事件描述在时间和空间相关性上的设计性,从而导致时空相关性缺失的问题。本文的目标是寻找一个参数化的映射,使事件数据尽可能地稠密集中,并保留时空关系,提出了一种使用可学习、数据驱动的事件描述方法。
采用的方法
基本思路
对于某个给定的事件流,选定一定的时间间隔,在该段时间间隔内,每个像素位置处均产生了一个事件顺序列,设计(或者生成)合理的特征集合,可以在每个像素位置上得到一个特征顺序列。然后,使用长短期记忆网络LSTM对每个像素位置处的特征顺序列进行异步处理,得到固定输出长度的输出向量,取定每个输出向量的最后一个有效元素作为当前位置的特征描述,整个图像上每个有事件位置的像素便可以得到当前时间段内的事件描述(是一个的矩阵),称为稠密曲面Dense Surface。
核心方法
本文设计的LSTM并不是简单地复制到每一个像素上(如果是这样,那内存成本将会高到令人发指的地步),相反,作者是使用同一个LSTM单元对向量化后(形状为)的全像素位置处的特征序列进行并行处理,然后将并行处理结果变形为。这样做的好处是减少了内存的消耗,如果在并行能力足够好的情况下,能够取得较好的时间效率(根据事件相机的分辨率,该方法使用当前的嵌入式设备计算仍然不可行)。
并行处理的核心方法是逐点归类方法groupByPixel,该方法如下图所示:
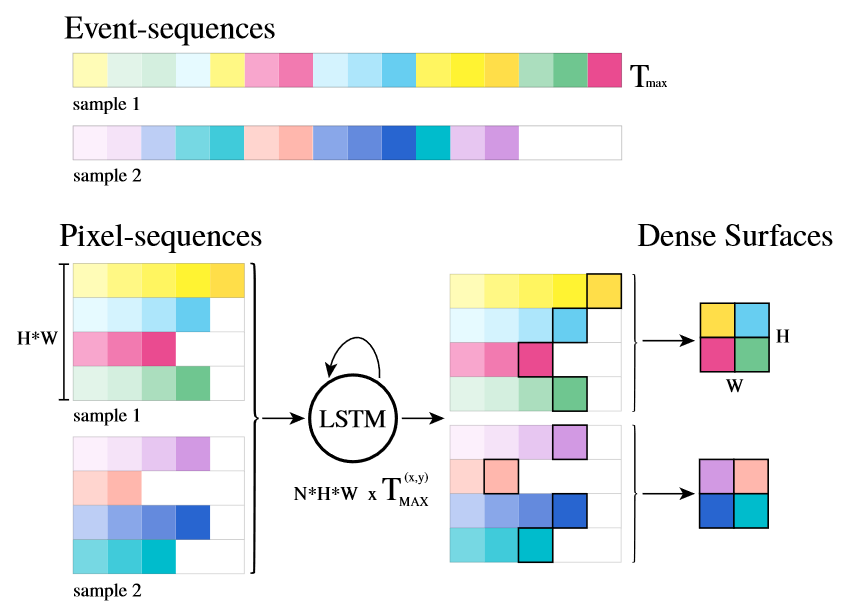
其中第一步就是将事件序列中的每个事件使用位置坐标对应至向量化的矩阵中,得到的结果是一个的矩阵,其中代表当前时间间隔内有事件的像素个数,代表整个像素平面内,事件个数最多的像素事件数量,最后一项代表特征集合的特征数量。
然后计算对应位置的特征、LSTM,最后,根据形状的变化关系,将上述结果反对应回稠密曲面中。
方法变化
本文后面又提出了一种方法变式variant,即使用个小区间对时间间隔进行平均划分,然后在每个小区间内使用上述方法,得到个稠密曲面,然后将这些稠密曲面连接concatenate起来作为最终的事件描述输出。
方法评价
本文方法其实给了我一种新的认识,就如同当年CV领域的卷积神经网络一样,使用可以学习的、数据驱动的事件描述确实是一种趋势,传统的手工事件描述肯定是跟不上发展的。设计这样的事件描述比计算机视觉领域稍微复杂的地方在于,需要考虑时间的影响,因为事件流数据是时间高度相关的数据,不宜使用固定、截取等操作强行消去前后时间帧的联系。
因此本文的第一个不足就是,本文使用的截取(哪怕是后面的变式)都是直接截取,两帧之间的事件没有重叠部分,相当于对随机信号使用了一个矩阵窗函数,引入的振荡噪声必然会对后期backbone网络产生不利效果。
本文的第二个不足就是只能使用离线数据计算,上述LSTM单元的运算用时必然较长,且资源占用较高,不能指望能够小型化和轻量化,更不能指望实时计算。
当然,本文的最大特点便是在事件描述领域引入了数据驱动的学习方法,此外,借鉴了自注意力机制,将事件描述的计算变成了可优化的方法,拓展了事件描述的应用领域。
第二篇文献
11月18日
文献名:SuperFast: 200× Video Frame Interpolation via Event Camera
IEEE Transactions on Pattern Analysis and Machine Intelligence
解决的问题
基于事件数据流和常规光学图像,如何解决在高动态情况下的视频帧插值问题,以取得高帧率的视频?
采用的方法
本文主要使用了U-Net网络架构,关于这个架构的知识补充可见这里。文章对视频的处理主要分为两种手段,即快插帧和慢插帧,然后使用U-Net将二者合并。最终可以得到帧率为5000Hz的视频,解决了高动态情况下帧速不足的问题。下图为本文的数据处理流程图,图中的四个Module,均为U-Net网络。
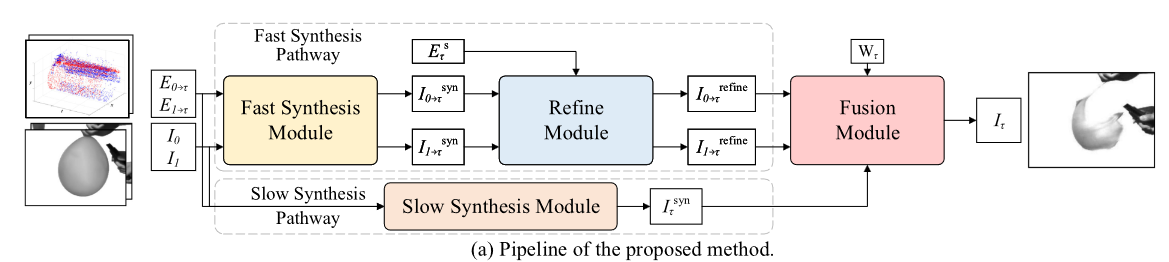
Backbone
本文大量使用到了U-Net,自行设计了一种损失函数,以某两帧图像的均值记为neg结果,以高速摄影机(曝光时长为)取得的真实结果GroundTruth记为pos结果,损失函数为不同网络层内输出的特征图到对应的pos特征图以及到neg特征图的距离之比,其优化目标为使用网络输出结果尽可能地接近pos结果,尽可能地远离neg结果。具体的损失函数如下:
式中的距离选取为范数。特征图即为输入图像的情况下,各层网络输出结果。
慢插帧
慢插帧用于场景运动速度较慢,或者不需要太多的高动态细节的情况。本文对慢插帧的处理较为简单,即使用前后相邻两帧的图像和对应时间戳内的体素栅格完成插帧结果。设时间戳0和1为两帧时间戳,又设时间为待插时间戳用来分割事件流得到两个体素栅格和,将两帧图像和两帧对应的体素格连接就可以得到输入张量,通过U-Net后输出插帧图像。
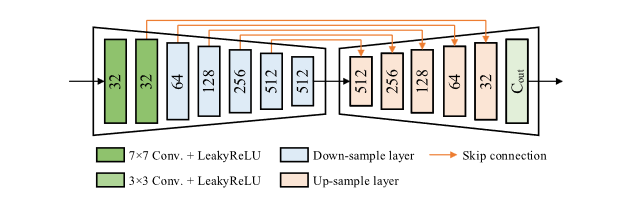
快插帧
快插帧不再使用手工设计的事件描述,而是使用基于SNN的特征提取器,取得的事件描述后与图像特征作对应融合,通过一个U-Net解码器完成图像插值。如下图所示:
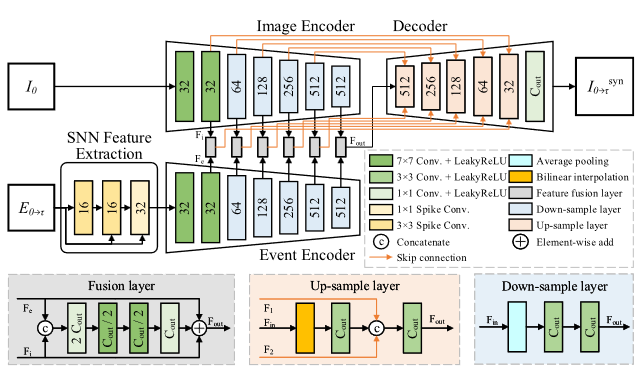
- SNN特征提取器中输入序列将直接与各层输出序列连接后作为下一层的输入,这一操作类似于ResNet,已经成为一种深度网络的设计思想,贯穿于本文各层网络的设计中。
- 事件描述与图像特征的融合:即Fusion Layer,对输入先使用卷积得到单维特征图,然后使用两层卷积完成数据融合,最后再恢复至原通道数,并与事件描述和图像特征直接连接,作为下一层的输入。
- 解码层,使用U-Net解码器完成图像插值。
- 图像精炼,文章认为单方向(从0到)上的快插有信息的丢失,因此从反方向(从1到)进行一次插帧,两个方向得到对应的插帧图像,,与其各自对应初始帧和以及共用的事件描述连接并输入至U-Net解码器,得到对应的精炼结果和。
快慢融合
从快插帧中得到的精炼结果和各自加权和,然后连接成为一个输入张量,经相同形状(但通道不同)的U-Net解码器后得到最终的插帧结果。
训练方法
本文网络较多,采用的是分批训练方法,即首先在ground truth上训练不带精炼模块的快插帧网络(其损失函数仅考虑快插帧结果与真实结果),然后加入精炼模块(损失函数修改为快插帧精炼结果与真实结果);同样地,先训练慢插帧网络,然后将慢插帧网络与快插网络结合进来,损失函数修改为带有正则项的最终结果与真实结果距离。
方法评价
本文主要解决了两个问题:一是使用事件流数据完成插帧;二是使用高速摄影机完成ground truth数据集的采集;文章为了保证得到的数据集在时间轴上对齐,使用了同步电缆连接两个相机,如下图所示:

保证在时钟上升沿和下降沿之间,高速摄影机完成一帧图像采集,然后具体怎么保证事件相机对应?我其实没有太明白。不过这确实是一种获取数据集时间轴对齐的良好方法。
本文的网络模型清一色都是U-Net模型,关于这个原因,作者并未指出,我认为一是出于简便,不用重复设计网络,简化了模型;二是能够保证事件数据和图像数据在对应矩阵空间中的平权,即二者处理的手段相同,保证处理结果两个输入是并重的。但是,这也算是本文的一种不足,从本文的数据结果可以看出,在测试集上能够取得较好的结果,尤其是在具有周期运动或者固定轨迹(如转盘转动)的高速摄影图像中,效果很好,但是在非周期的结果上,表现稍差。在泛化测试中,表现结果不如测试结果,可能与模型的单一有关。
同时,本文并未测试在光照变化的情况下的视频插帧,这与其背景介绍的不同光照条件下的视频插帧需求有些不符,至少没有提到,算是本文的一个欠缺吧。、
第三篇文献
文献名:Robust spike-train learning in spike-event based weight update
文献有些早了,主要提出的是对训练学习率和训练梯度的两个方法,提到脉冲神经网络的模型是SpikeProp,具体是怎么实现的原始文献已经找不到了,竟然是Eindhoven的一篇博士论文。(厚着脸皮去要原文倒也不是不可以)
解决的问题
本文比较水,就是考虑如何将两种ANN的训练方法RProp和QuickProp和某种提出的SNN框架SpikeProp结合起来,实现对该框架的快速训练。
采用的方法
简要介绍一下SpikeProp,这是由Eindhoven大学Bohte教授于2003年其博士论文中提出的SNN框架,其采用的误差函数是脉冲时间戳的欧氏距离,即,是一种较为精确度量两个脉冲序列差异的范数,但是计算的成本非常高。反向传播的方式与ANN相同,但是误差对梯度的偏导数较为复杂(原文尚未给出)。
本文提出的修改方法较为简单,主要有两点:
- 修改RProp:RProp原为Resilient Prop即学习率自适应梯度变化,根据当前收敛情况调整学习率的幅值和符号。本文一改使用权重梯度作为自适应变量,而是采用两个刚性的权重上下限w_\max,w_\min作为学习率变化的门限值。
- 参考QuickProp,使用权重梯度的一二阶导数之比求取梯度,以代替原文非常复杂的偏导数,同时,引入momentum项,以加速收敛。
方法评价
本文对方法进行了仿真实验,得到的效果在XOR问题上较为理想,但是其他数据集等尚未测试(与年代有关)。由于不了解SpikeProp的具体框架,其实这篇文献不太好评价。






