
图像检测模型详解
前言
图像检测领域是一个较大的分支,目前主流的方法是YOLO,但是R-CNN系列也是非常经典的方法,有必要对这两种类型的方法 作深入的了解,才方便 后续的方法 创新。之前一直不理解YOLO模型的Anchor机制的具体含义,直到4月17号才突然明白,原来指的是一种耦合关系。
R-CNN系列
文献
Rich feature hierarchies for accurate object detection and semantic segmentation
Fast R-CNN
解决的问题
检测Detection一词的定义,在文献Regionlets for Generic Object Detection提到过一嘴,本意是从一大堆候选的子区域中,选出来带有物体的区域(也可以是超像素),进一步延伸到了对这个子区域按标签分类,这就是当前深度学习领域检测任务的由来。
这两篇文献,归为同一个类,都是R-CNN检测网络的祖宗之法,是最早提出基于区域的CNN检测方法的文献,其主要解决了CNN不能直接用于检测任务的问题,可谓是开检测领域 深度学习之先河。
主要内容
基于区域的检测方法 ,是这两篇文献 的核心内容。
R-CNN
R-CNN的R指的是Region,言下之意是按区域对目标实体作检测,可以使用原始文献的流程图来描述:
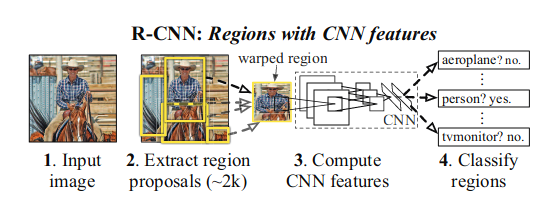
即首先按区域提取的方法,得到候选区域(可能包含了待检测的物体,也可能不是),然后对这些区域进行仿射变换得到符合CNN分类网络输入的大小,完成 分类加标签。区域提取的方法 ,文中提到了两种,一种是regionlets,子区域检测,是在已知一定数量的图像的基础上,对图像中某个特定特征区域 的检测(例如手部的检测),得到的是特征在图像中各处的小区域并集。
同一个Regionlets只能检测一个特征,如果要完成多个特征的检测,则必须加入多个检测Regionlets。
另一种方法是选择性检测,论文Selective Search for Object Recognition中采用的方法是对超像素块按多种度量手段层次聚类,得到较多的候选区域,此外也可以使用固定网格大小的聚类窗口。
使用这两种方法得到一系列冗余的候选区域后,可以直接对这些区域按以上方法处理产生分类框。
这一步忽然就解释了为什么检测都要把物体分在矩形框里,因为只有这样才能得到一个方形的图像以便于分类。
Fast R-CNN
这是在R-CNN基础上的改进版本,将深度网络VGG块引入至CNN以提高检测模型的训练速度 和推理速度。在模型的网络构成上作改进,如下图所示:
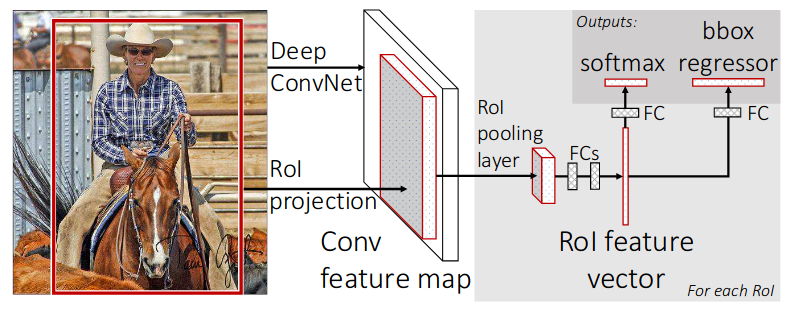
其中分为以下步骤:
- RoI区域最大池化:将候选区域根据VGG网络的输出大小和变换关系投影至特征图上,然后对该投影区域计算 最大池化,产生固定大小的特征向量。
- 特征向量输入至全连接层中作回归计算,经过两个通道的回归框计算后,得到输出框的类别和位置。
训练方法
两篇文献都 指出,由于检测数量集的标注量要比分类问题更加精细,且标注的空间是连续空间,因此不能像分类问题那样直接使用监督学习完成模型训练(欠拟合)。作者指出了两种可能的训练方法,均是采用了预训练+微调的方法:
- 自监督预训练+有监督的微调。自监督方法 能够增强模型的描述提取能力,在有一定的描述提取能力的基础上,再加入监督学习以完成 下游任务,可以有效避免直接训练过程中的欠拟合问题。
不得不说这和基于GPT的语言大模型的训练方法 一模一样,真是毫无理论创新。
- 大样本监督预训练+具体问题微调:这种方法多是在附加的分类数据集上完成CNN模型的预训练(监督指令不带有检测 的信息),然后在检测数据集上微调CNN模型 使之输出检测框和分类标签,同时对数据集作数据增强。
不同之处在于,Fast R-CNN在训练时,使用了多任务损失函数,即对检测框的位置和类别同时进行监督,这样可以使得模型在训练时更加稳定,同时也能够提高模型的泛化能力。误差项分为类别误差和框误差,其中是真实类别,是预测类别的概率分布列,是真实框,是预测框,是宽高,是中心坐标,是一范数和二范数结合的平滑函数。
内容评价
这两篇文献由浅入深,前者将检测问题从一个巨大的连续空间回归问题抽象为离散的分类问题,后者将该问题的手工设计环节进一步省略,改为直接在特征图像上完成对物体区域的定位,具备了从端到端的检测任务特性。两篇文献正式让检测问题成为了深度学习的一个应用分支。当然两篇文献的问题现在已经被研究得很多了,这里指出来也没有必要。
YOLO系列
YOLO系列也是较为流行的检测框架,主要特点就是速度非常快,远远超过R-CNN等框架,其采取的手段是网格化+锚点回归,比R-CNN相比,省去了对位置提取的计算。
YOLO简述
YOLO模型取材自R-CNN,本意是为了解决R-CNN在速度上的巨大瓶颈,因此其文章You only look at once言下之意就是对所有的网格块只作一次运算,而不像R-CNN那样先提取、后回归,运算有冗余的成分,因此在原理上,速度将快于R-CNN,同时,也在原理上精度将不优于R-CNN(因为直接计算而不是提取后计算,引入的非物体像素必然造成回归误差)。
关键创新
引入网格划分方式是YOLO模型对R-CNN的巨大飞跃,这一步直接取消了区域提取步骤,如下图所示:

对于全部输入的图像,以同样的划分方式对其进行划分,得到个输入网格,经网络处理后,产生一个输出向量,将直接包含该网格内部的物体信息和检测框信息,一步就完成了区域提取与回归,尔后再通过网格的并集运算和类别得分计算,得到检测框及类别。
锚定机制
锚定机制Anchor是YOLO模型中的高频词汇,对于我而言,是一个比较晦涩的概念。
因为我花了两周才明白它到底是什么意思。
锚定机制并不是YOLO的首创,其根源来自于R-CNN。设检测网络的函数函数关系式为,式中,是输入图像的分辨率,是待检测的物体个数,是待检测的类别数。在YOLO模型中,锚定机制具体指:
检测网格输出的检测框位置、尺度信息,将与检测网格的位置强相关。
该过程可以使用YOLOv2论文中提到的如下公式解释:
上式各项的几何含义可以参考下图:
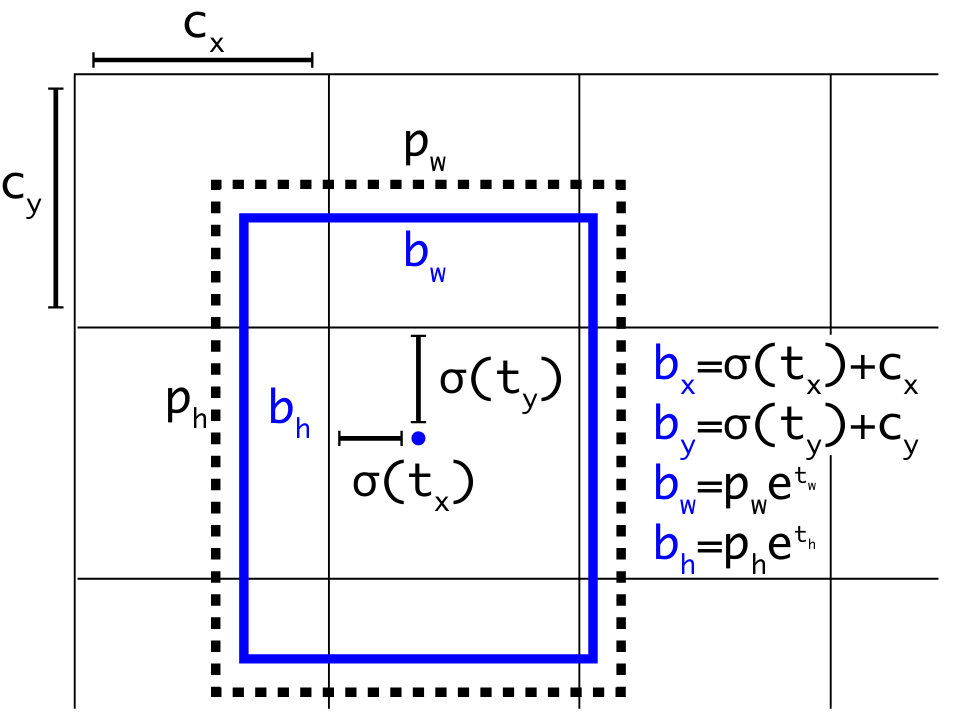
该公式充分说明,YOLO模型的锚定机制将整个大Hilbert空间的回归问题(如的矩阵位置空间)的回归问题,压缩成为了一个小Hilbert空间的回归问题,如。
两个空间的势是相等的,数学上并没有任何改变,但是由于训练的网络并不是这个空间中的全满射,因此在有限的训练样本集中,后者得到的训练集样本点密度明显高于前者,训练得到的网络函数能够在最小均方误差的意义下更加逼近待求解的全满射。因此使用锚定机制的YOLO保证了回归原理上的精度不降低。
并不是锚定保证了精度,而是锚定后的样本空间密度产生的网络拟合能力保证了精度。
因此原理上,不使用锚定机制也能够保证YOLO模型的精度,这便是自YOLOv6之后的Anchor-free发展趋势。
训练损失
根据锚定机制的解释,自然可以理解为什么YOLO模型的损失函数是RMSE(甚至类别也是RMSE),原因有二:
- 回归问题是最小均方误差意义下的最优解,因此RMSE自然是首选;
- 锚定机制带来的解空间压缩,是在RMSE意义下的压缩,如果使用其他的距离测度,不一定是最优解。
因此YOLO函数的损失函数是:
最终的损失函数是以上各式的正则加权和。
从网格到检测框
网格是固定在每一幅输入图像上的先验知识,如何从网格信息中得到检测框,是YOLO模型提出的另一个巧妙解决方法——采用基于非极大抑制的聚类,聚类仍然使用K-means聚类,但是聚类的距离是精心设计的IoU距离,即:
在YOLOv2中,选取的聚类超参数是5,说明该模型仅能处理单图中不超过5个物体的检测问题,聚类方法制约了多目标检测的能力。不过,图像目标数为5已经是较大的数目了,可以较好地处理大多数检测问题。
新发展
YOLO系列发展迅速,如今已经得到了YOLOv9的主线框架和一大堆支线框架,牢牢占据了图像检测领域的主流地位。近年来有一些新的发展趋势,对YOLO模型的精度问题有改进思路,其中一条是无锚化发展Anchor-free,另一条是多尺度融合发展Multi-scale,这两个方向都是为了提高YOLO模型的精度,但是在速度上会有所牺牲。
无锚定机制
在YOLOX论文中提出了一种无锚的机制,如下图所示:
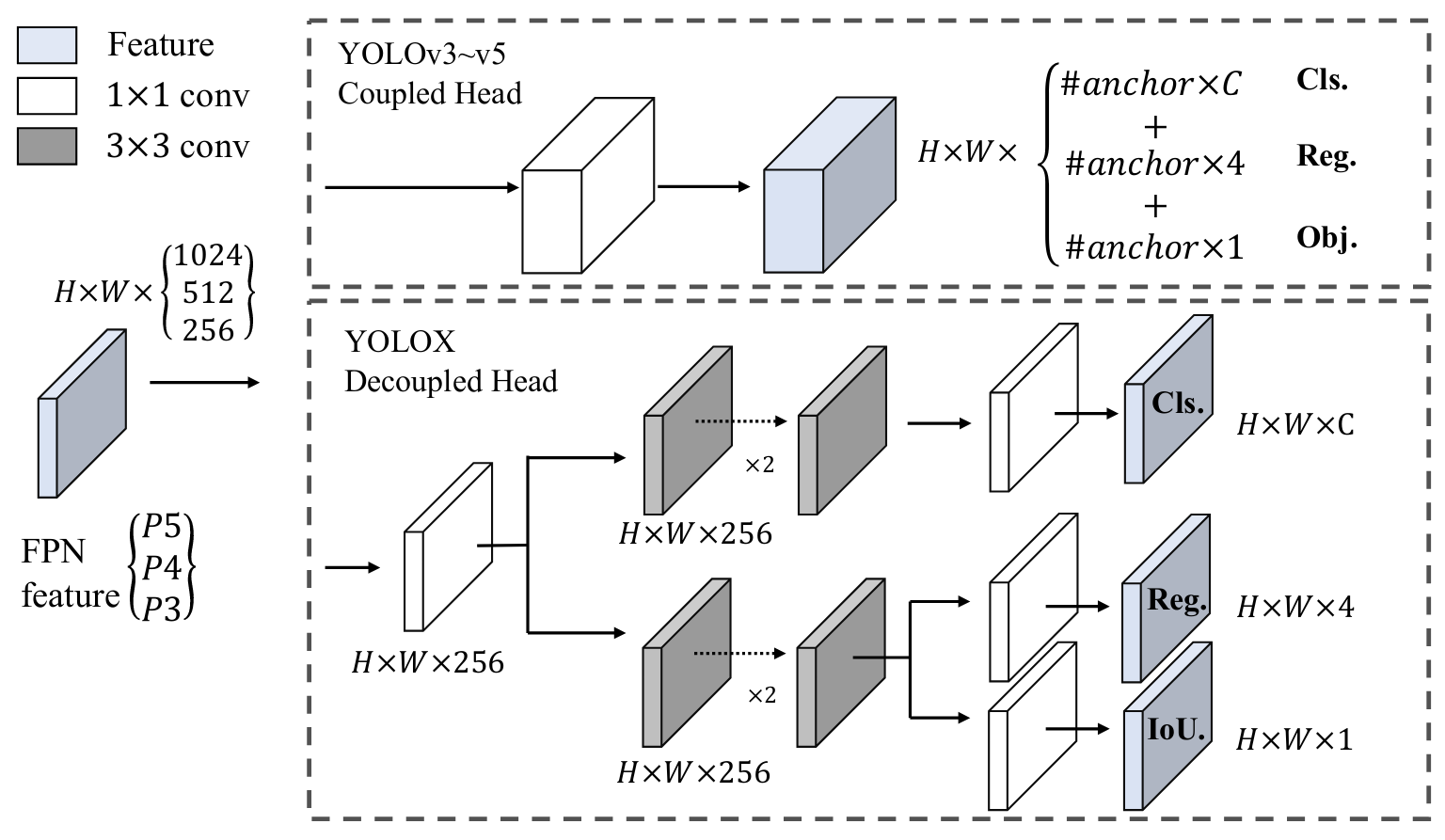
文章采用的方法也是较为简单的,即直接将检测网络的通道解放出来,每个平行通道经全连接层解调后输出一个检测数据,将类别、位置和置信度信息分离,实现了一种意义上的无锚。无锚后的检测网络检测精度mAP得到提升。
其他系列
例如SSD。




