
24年5月进展
第一篇文献
Boundary-Aware Divide and Conquer: A Diffusion-based Solution for Unsupervised Shadow Removal
解决的问题
本文提出了一种融合扩散模型的图像去阴影方法,该方法能够在无监督的条件下使用扩散模型强大的生成能力完成对阴影部分图像片段的插补。
主要内容
本文内容主要分为两个部分,其一是阴影图层分解模块,如下图所示:
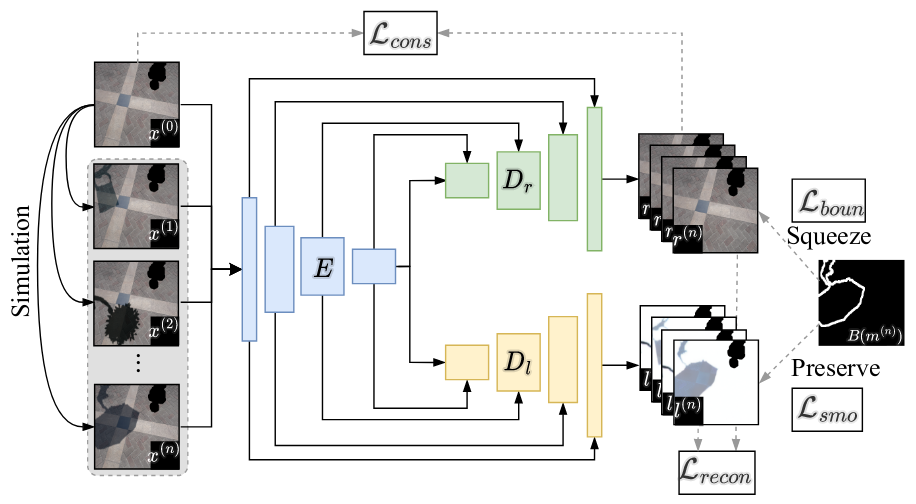
该模块自带数据增强功能,能够从当前已有阴影的图像上自动再生成合成阴影,然后通过训练两路编码-解码器模块完成对阴影图层的提取,包括提取阴影区域、提取阴影边界,使用四个子损失函数完成训练,分别是:
- 图像重建损失,即去阴影得到的预测图像与真实无阴影图像的范数误差;
- 图像一致性损失,即合成的不同阴影图像经过去阴影后产生的预测图像之间的范数误差;
- 明暗交界损失,即阴影区域和非阴影区域的交界线像素灰度的范数误差;
- 平滑性损失,即不是阴影但是被分进阴影区域的像素灰度的范数惩罚。
由以上四项构成正则项完成对阴影图层分解模块的训练。然后对预训练得到的模块,设计如下DDPM模型:
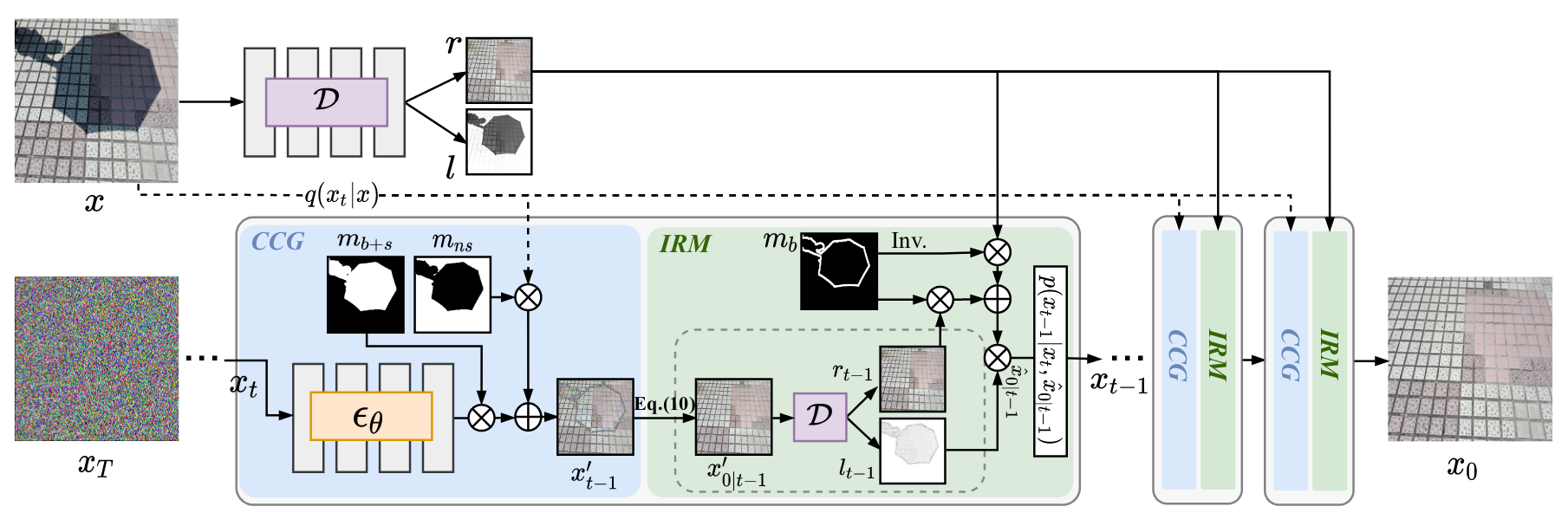
模块分为语义条件生成Context Conditioned Generation,CCG和迭代光度层保持Iterative Reflectence Maintenance,IRM,由CCG层利用阴影模板提取到的图像块完成图像内插补inpainting,然后内插补所得图像经阴影图层分解完成阴影提取和边界提取,由原始图像的提取结果作为先验信息与生成结果加权融合,得到单步生成图像,然后完成下一步的扩散过程直到迭代结束。
方法评价
本文方法直观上的理解就是反复使用扩散模型的内插补功能完成对阴影部分的内插补,因此整个模型的性能将完全取决于预训练得到的阴影图层分解器的性能。本文并没有加入扩散模型的条件引导项,而只在阴影区域完成扩散计算,因此在阴影部分得到的内插结果是以分解结果为均值的高斯分布采样。严格的讲,本文并没有用到扩散模型的精髓即条件引导,不过生成的效果尚可。
第二篇文献
Condition-Aware Neural Network for Controlled Image Generation
解决的问题
本文相当厉害!是Nvidia的实习生一作所发,旨在解决当前的图像大模型DiT在细分领域上需要反复重新训练耗时耗力的问题,提出只需要训练一个基本大模型,然后在不同的领域处直接对基本大模型的某些层权重按条件融合进行修改即可,能够节省相当的训练资源。
主要内容
本文的工作流框架如下图所示:
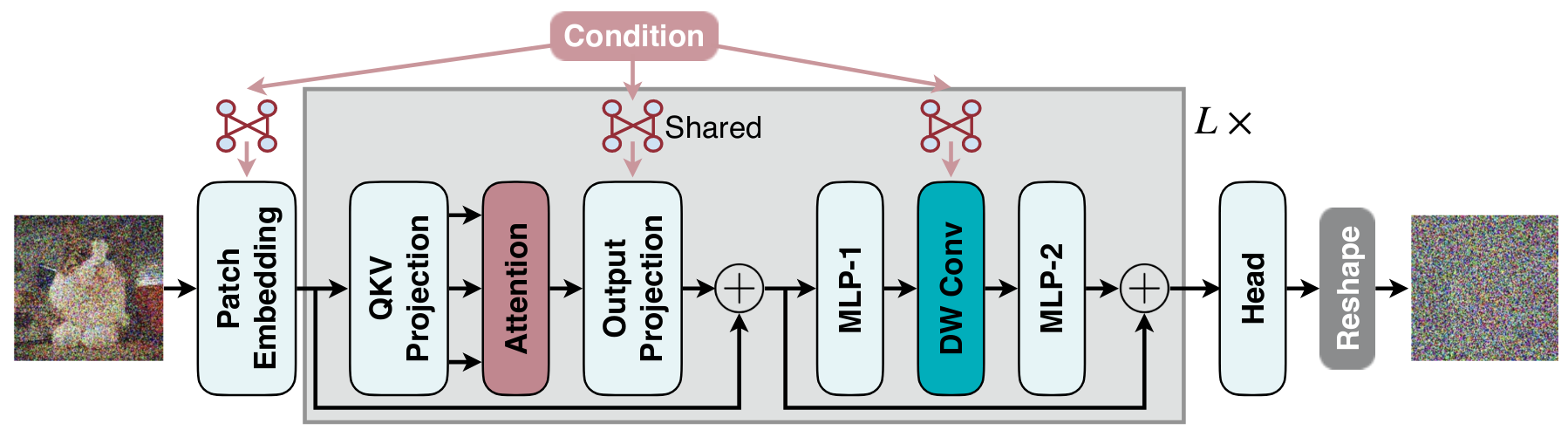
作者对DiT模型的块嵌入层、输出空间投影层和深度卷积层加入共享权重的条件权重生成模块Conditional Weight Generation Module,使用该模块直接将外部提示所产生的条件融合进入大模型中,完成扩散的正过程和逆过程训练。作者进一步研究了融合过程的方式,即可以通过按组卷积融合将不同批次的输入数据共享该条件输入融合项,如下图所示:

方法评价
本文的方法算是对现在大模型所面临的常见问题的一个解决方案,即当前大模型大多是专用型模型,只在特定的领域中表现出色(与训练的数据集有关),而真实的通用大模型需要在不同的领域上均有良好的表现,因此往往需要反复利用不同的数据集微调甚至训练,得到不同的专家模型,然后设计顶层大模型接口,使不同的问题由不同的专家模型解决并回馈。本文提出可以使用某一个较大的模型,通过输入提示不同的条件项完成对模型的动态微调,确实能够节省相当的训练资源和部署资源,对于商业化运营相当重要。
第三篇文献
KAN: Kolmogorov–Arnold Networks
解决的问题
突然爆火的一篇新范式神经网络文章,作者指出了基于固定激活函数神经元搭建而成的MLP网络在面临回归问题的窘境,提出使用可学习的激活函数网络层(科尔莫戈洛夫-阿诺德网络Kolmogorov-Arnold Networks,KAN)取代MLP,有望解决MLP在回归问题上的差劲表现。
主要内容
数学原理
KAN与MLP的区别如下表所示:
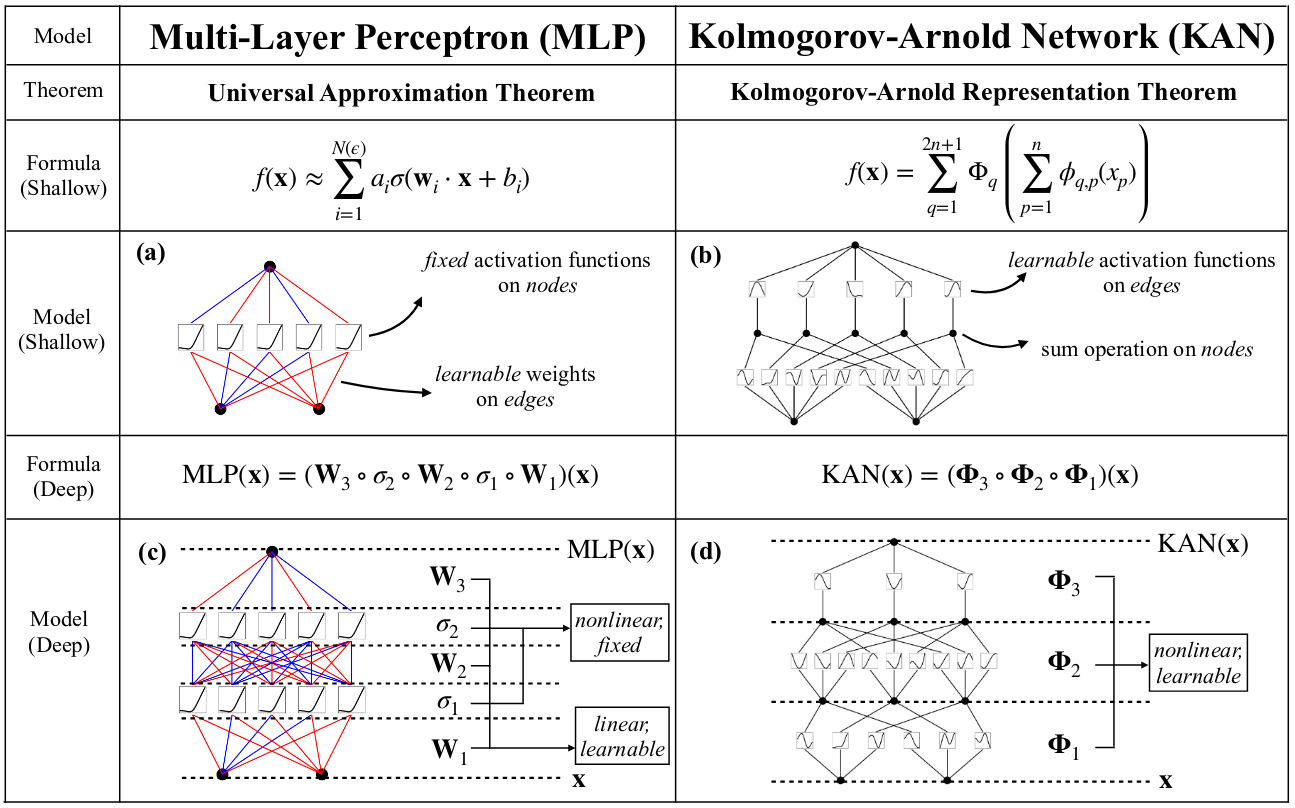
可以看到,KAN在保证连接权重可以修改以外,还进一步加入了可学习的激活函数,同时,神经元之间的连接也将是动态的。KAN网络的数学基础是K-A描述定理,即对于某个连续函数,均可以使用两层函数逼近:
其中的每个描述函数甚至可能不是平滑的,在原始的MLP看来,KA描述定理最多只有两层连接,注定不能用于深度学习领域。作者提出,可将KA描述定理拓展为KA层,即对于每一层神经元,其接受的输入和产生的输出将满足:
即将KA描述定理的第二层单独抽离出来,作为独立存在的神经网络层,作者进一步假设工程实际中使用到的函数都是光滑的,其KA描述函数子也将是光滑的,因此KAN成为可能的神经网络范式。
训练过程
实际的激活函数是Hilbert空间的任意取值,不能通过梯度下降的方法完成优化,因此作者提出了一种简化版的我激活函数簇,即使用B样条曲线的和式作为单个神经元的激活函数,如下式:
因此训练过程可以学习的参数就是各个B样条网线的加权值,即,此外,作者进一步设计了动态的剪枝算法,能够使用KAN网络中闲置的神经元自动剪除,使网络的结构尽可能简化。
方法评价
本文提出的KAN网络是对MLP的一种有力拓展,极大增强了MLP对多元非线性函数的拟合能力,增强了MLP在回归任务上的表现,网络的可解释性得到提升。但是本文提出的方法局限也非常明显,即KAN网络的单个神经元复杂程度远远超过了MLP的单个感知神经元,因此如果要使用KAN构成诸如CNN、RNN等复杂网络时,将不可避免地造成网络参数急剧增加,而KAN自带的剪枝算法也并不能直接对神经元进行剪除(否则CNN等结构将被破坏),因此本文的网络实际上只是在回归领域对MLP的一种拓展(作者也承认了这一点),而在其他领域的应用还有待进一步研究。
第四篇文献
Wasserstein GAN
解决的问题
提出了有关生成式模型目标函数的一般性方法,即当两个概率分布在高维空间中的没有交集时,(此时KL散度失效、JS散度为常数、变分距离为常数)应该如何处理?作者指出可以使用Earth Mover距离,又称Wasserstein距离,来度量两个分布之间的距离。
主要内容
文章有大量晦涩难懂的数学公式及其证明,确实超出我的认知极限了,这里就不放那些晦涩的公式了,只放一个最直接的结论,即Wasserstein距离的定义:
任取两个相同空间中的概率分布,用1范数定义的Wasserstein距离为:
其中是所有边沿分布为的分布簇。本式仅具有原理上的意义,不具有工程应用的实际作用。通常可以认为现实意义下的函数都是满足推论:任意有限维度的向量值映射的Lipshitz系数均有界,且期望值有限。因此可以将上式改写为:
其中是Lipshitz系数,进一步可得该式的梯度为:
其中,为增广向量值函数,将的随机变量增广至联合分布空间。
方法评价
本文的方法在原理上进行创新,基于提出的Wasserstein距离,GAN生成的图像质量较其平替类型取得较大的提升。本文进一步指出,基于KL散度的概率生成模型都需要加入噪声,正是因为KL散度在概率空间不相交的地方无定义,而加入噪声不可避免引起了数据集的退化,有碍生成图像的质量。实际上使用Wasserstein距离可以避免手工添加噪声的方法。但是Wasserstein距离的收敛性弱于KL散度等,其训练得到的模型将更容易收敛,也更容欠拟合。
第五篇文献
SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing
解决的问题
本文解决了扩散模型的条件控制图像生成的问题,不需要单独外接控制器和控制模型(如条件引导模型等),只需要在原有的扩散模型的UNet噪声估计器上增加一步跳步连接融合模块,直接可以实现以图像的形式,输入至扩散模型中完成控制生成。
主要内容
本文提出的网络框架构形如下图所示:
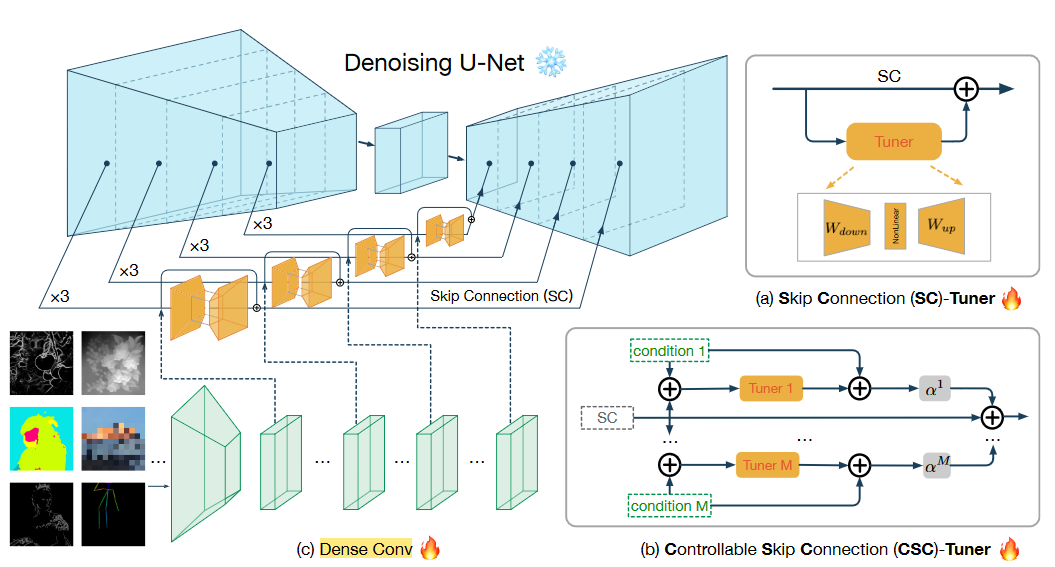
需要额外加入一个编码器环节,将输入的控制图像编码为跳步环节相同尺寸的大小,然后与跳步通道直接相加,作为跳步项的偏置量;此外再通过另一个调整网络tune1、tune2以至tuneM,实现对条件图像与扩散跳步图像的深度融合(基于UNet),并最终经尺寸变换后加在跳步的偏置量上,作为输出的跳步项参与图像生成。图中给出了两个可能的融合方式,即自偏置调整SC-Tuner和控制偏置调整CSC-tuner。
方法评价
本文提出的方式在一定程度上脱离了扩散模型自身的采样步骤,实现了扩散生成图像的模块化和程序化,更方便在不同的模块上调试、验证扩散模型的生成效果。本文的方式还能够实现较好的生成效果,使用起来也较为便捷。
第六篇文献
SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS
解决的问题
相对于Wasserstein距离,这篇更是重量级,主要的工作是将两种不同类型的扩散模型的框架整合统一了,归纳出其中相同的组成原理,即扩散模型都是在求解随机微分方程的逆过程解,只是在解的过程中有不同的表达形式。
主要内容
扩散模型见诸机器学习和深度学习,最早可追溯于2015年的Deep unsupervised learning using nonequilibrium thermodynamics,最早使用非均衡的热力学原理实现无监督学习。在2020年DDPM问世之前,亦有基于朗之万方程Score matching with Langevin dynamics的扩散模型得到学术界的研究。这两种扩散模型可以使用分数模型统一归纳为随机微分方程的解,如下图所示:

两种模型都可以使用分数Score模型描述生成过程中前后步的梯度变化,并使用换元法完成随机采样。
SMLD型扩散模型
离散的随机差分方程满足:
其中,是步长控制量,是分数函数,用于拟合随机差分方程的梯度,是噪声系数。
DDPM型扩散模型
离散的随机差分方程满足:
与上述方程是类似的,只在系数的分配上不同。
两大类型的扩散模型的目标都是优化梯度估计项的参数,即,因此其优化目标函数应当也是相似是,即都需要使得分数函数与真实的图像分布梯度相似:
两者的计算是类似的,但是具体权重分配、期望求解的概率分布对象是不同的。本文将以上两种类型的随机差分方程在时间连续的意义下抽象为随机微分方程,进一步统一为分数模型,并结合VE的SDE模型和VP的SDE模型,将以上两种扩散模型结合为一种,得到的一种新的随机微分方程,即:
其中是维纳过程。将该微分方程离散化,得到随机差分方程并求解其生成过程,可以得到更高质量的图像生成模型。
方法评价
本文工作的最关键贡献是抽离出了扩散模型的一般性特点,即随机微分方程,并使用分数模型逼近随机微分,实质上也给出了一种形式的条件引导项,即基于梯度的引导项。本文工作为基于分类器梯度的条件引导论文提出奠定了基础。
第七篇文献
Momentum Contrast for Unsupervised Visual Representation Learning
解决的问题
对比学习的里程碑式的著作!本文以前有很多种,本文以后,只有MoCo(有点夸张)。实际上本文解决的正是将各种各样杂乱无章的对比学习范式统一抽象为一种类型:基于字典查找的学习。
主要内容
本文归纳的各种不同的对比学习模型如下图所示:
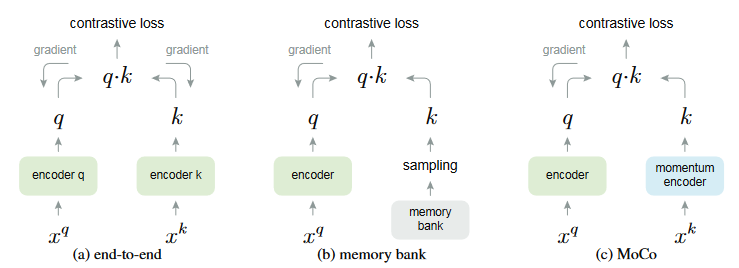
预训练的核心在于对数据集的整体分布把握,而对比学习采用的方式类似于聚类分析,把数据内部所具有的相似性不断放大(拉近),不相似性不断疏离(拉远)。通过两个平行的分支(通常为两个结构相同的编码器,如图像的卷积编码器或者自然语言处理的编码器)。编码器充当的是字典的作用,用于将输入的数据映射为某个高维空间的特征向量,编码器并不是对比学习预训练的核心。
对比学习预训练的核心在于梯度反向传播的手段,本条将于后文详述。
MoCo模型
MoCo模型作为第一个系统性分析后提出的对比学习框架,其应用不局限于某个具体的领域,可通过修改编码器的将其拓展至图像、音频和自然语言处理领域。其结构简单,结构如上图所示,这里陈述如下:
- 两个并行的分支编码器,其中一个编码器通过对比损失的梯度反向传播更新参数(记为主动分支),另一个编码器将主动分支的参数与本身参数经动量加权后完成更新,即满足:,通常;
- 对比相似度通常使用余弦相似度,即对于两个编码向量,其相似度为;
- 使用正负样本的对比求解对比损失,正负样本分别计算对比相似度,对比相似度作为计算交叉熵损失的输入,即:
模型训练技巧
对比学习的最主要问题是,训练得到的模型极其容易崩塌Collapse,具体体现在:模型的对比损失在极短的时间内迅速下降至下确界(例如0),如下图所示:
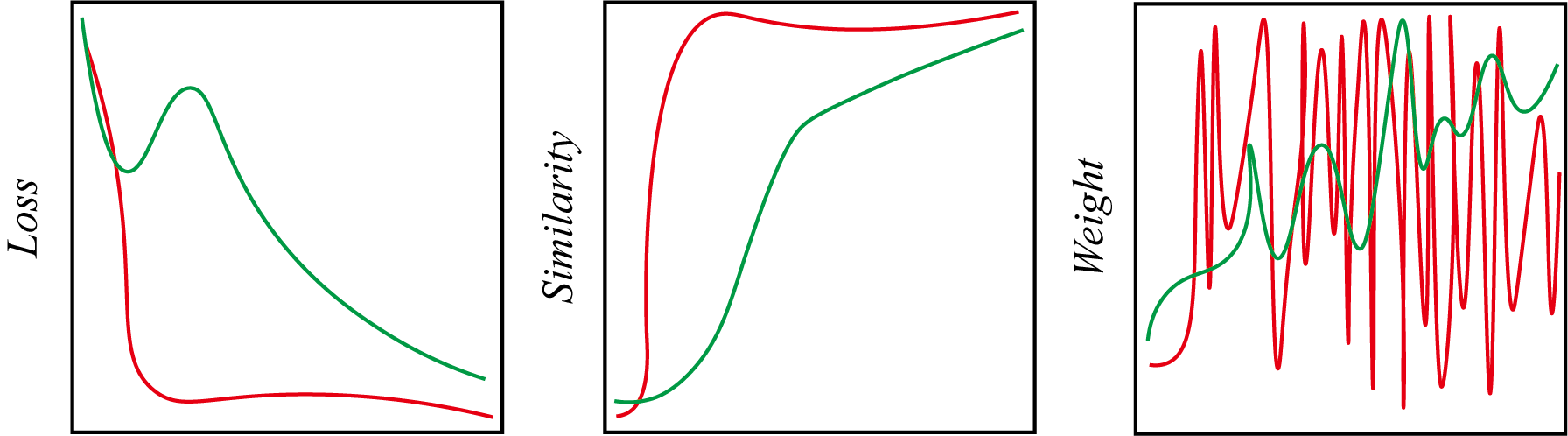
其中红线代表的是模型崩塌时各项监测指标的结果,绿线代表正常训练的对比学习过程,崩塌往往代表模型收敛至恒等变换。为了制止模型的崩塌,通常要采用一系列技巧:
- 数据增强:输入数据将作变换(如图像变换),保证输入不是完全相等同的;
- 动量更新:为了避免两分支收敛至完全相等(产生恒等变换),两分支采用的参数更新一定不能相等(不可使用相同的更新手段,例如同时进行反向传播),可行的方式是动量更新,或者逐个更新;
- 负样本:使用交叉熵分类损失能够有效增强模型的训练稳定性,前提是必须人为限定正负样本(即主观上判定的不是相同类的编码向量),通常是不同类的图像或者文本;
- 批归一化。
方法评价
MoCo方法首次归纳出对比学习的诸多特征,其设计思路也主导了其后的多个对比学习框架,该方法仍然沿用了正负样本对比的思路,经过预训练+微调后的模型在ImageNet等数据集上的表现可以超过监督学习预训练+微调,但是直接预训练结果仍然无法超过监督学习,且负样本的设计限制了其使用范围,即必须存在显著的类别差异,否则模型将崩塌。
第八篇文献
A Simple Framework for Contrastive Learning of Visual Representations
解决的问题
本文是在MoCo提出后的又一篇视觉领域对比学习重要工作,其解决了对比学习中效果不佳,模型的描述提取能力比不上监督学习的问题——即使用一次投影网络。
主要内容
本文的框架与MoCo类似,仍然是双分支、带负样本且使用InfoNCE的对比学习网络,如下图所示:
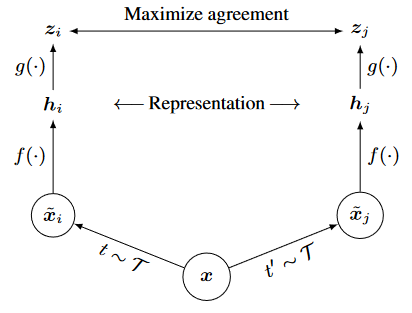
核心的创新在于编码器后的投影网络,该网络事实上提供了对编码向量的修正项,使得编码向量由数据增强带来的随机性得以消除,增强了对比学习的稳定性。
本文的另一处贡献在于,研究了多种数据增强的搭配组合方式,结论是:使用基于随机裁剪和颜色通道变换的数据增强方式组合带来的效果最好,如下图所示:
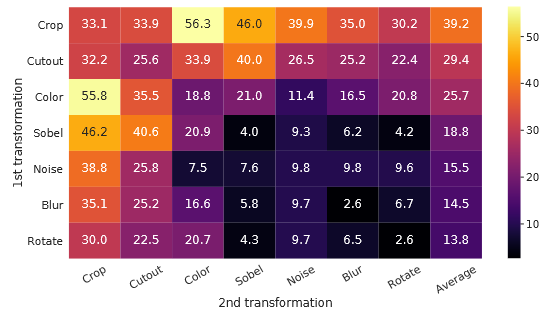
其中数值是预训练模型的线性探测结果linear probing,数值越高代表模型的描述提取能力越强。
方法评价
本文将MoCo提出的对比学习框架应用于视觉任务,并通过增加一个简单的投影网络,直接为对比学习的效果涨点10%以上,可谓是四两拨千斤。本文的工作也被后续没用,凡是对比学习均使用了投影网络。
请注意:投影网络仅用于对比学习预训练,预训练完成后该网络将被丢弃,不会参与到模型的微调中。
但是本文的方法仍然需要负样本,且训练迭代的Batchsize极大(据说达到了4096,对应的负样本个数是16382),难以实际应用(或者说仅能用于大规模数据集和大模型上)。
第九篇文献
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
解决的问题
显著突破!本文首次舍弃了负样本,提出完全自对比框架,其核心思想类似于生成式特征提取,即自身与自身对比,不需要额外的负样本。框架的示意图如下所示:
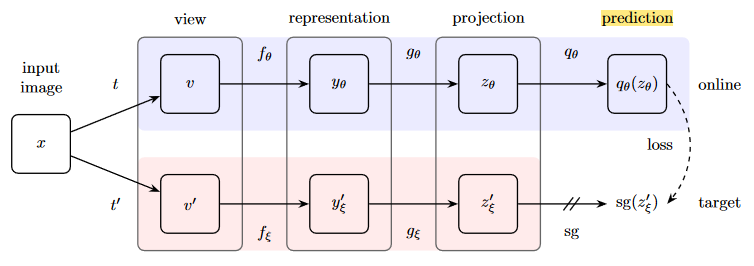
该框架在SimCLR的基础上,在主动分支上复制了一份投影网络,其结构与投影网络完全相同。在训练的技巧上,舍去负样本后,仅需要将同一个输入量经两个不同的数据增强器后加入到编码器编码,并经过一次投影网络对齐,仍然沿用了余弦相似度(但是不再使用InfoNCE了,因为没有负样本)。主动分支的参数更新仍然使用反向传播的梯度,而分支的参数更新使用动量更新。
关于BYOL为什么不使用负样本也能保证网络模型不崩塌,网络上曾经提到过一个观点:
BYOL非常依赖于批归一化,批归一化相当于提供了负样本中心,因此对比时相当于使用输入向量与负样本中心做对比
但是该观点被作者驳斥,作者经过实验认为:
批归一化确实能够增强模型训练的稳定性,但是它并不是必需的,因为即使加入批归一化,模型仍然会崩塌;而加入批归一化,模型仍然会崩塌。
当然作者的驳斥也是显得有点无力的,因为依靠实验说明相同情况下批归一化的加入与否不影响模型的崩塌情况并不能说明批归一化与模型的崩塌无关。我的理解是,BYOL模型不崩塌的另一种原因是,BYOL实际上是类似于VAE的生成式预训练模型,其目标是生成自身相同的特征向量,因此完全不需要负样本。而余弦相似度实质上提供了类似于MSE的作用,即拉近两个向量在单位球上的距离,因此BYOL是不带解码器的生成式预训练模型。所以BYOL的成功并不是因为批归一化,而是本身的生成式特性。
方法评价
BYOL方法在操作上较为简易,因为免除了负样本的修正,基本做到了开箱即用,使用起来也较为容易。但是该方法的问题在于,对比学习没有起到对比聚类的作用,而生成式学习又没有达到逐像素的精细化度量,因此效果上都比不过上述两类的SOTA,但是其提供了新的思路,引入自对比,在一定程度上可以增强基于监督学习网络的描述提取能力,因此基于BYOL方式的训练手段可以用在微调中。
第十篇文献
Exploring Simple Siamese Representation Learning
解决的问题
另一篇何教授的力作,再次为对比学习中关于模型崩塌无休无止的争论划上了一个逗号,并在SimCLR、MoCo、BYOL的基础上讨论了制止模型训练崩塌的方法。
主要内容
Siamese翻译为孪生,即两个完全相同的网络结构,其结构如下图所示:
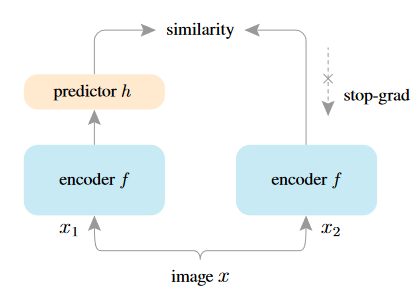
采用了非常简化的网络框架,舍去了负样本的要求,同时,相对于BYOL再作一步简化,即不再使用动量更新,而是直接使用相同的网络,但是在一端加入投影网络并使用梯度反向传播完成梯度更新,在另一端中断梯度的计算和更新。该网络框架的训练和设计是为了验证:
- 模型的崩塌与负样本无关,但是负样本的存在会显著提升模型的训练稳定性;
- 模型的崩塌与批归一化无关,但是批归一化的引入可以增强模型的效果;
- 动量更新对于模型的崩塌有帮助,但是它实现了学习率的减小,只能延缓模型的崩塌,并不能制止。
作者认为,孪生网络真正的对比崩塌关键因素是梯度的传播方式,即必须通过单分支更新,否则较大的梯度将导致模型退化为恒等变换映射。而文中采用的交替更新方法,事实上提供了如期望最大化Expect Maximization的效果,动态地完成了参数的更新。
方法评价
本文的实验讨论在一定程度上终结了持续不已的争论,给对比学习的模型训练方法设计指明了方向,即必须通过单分支更新才能保证模型训练的稳定性。文章提出的孪生网络也对BYOL和SimCLR作新的简化,在保证模型预训练效果的前提下,进一步提升了模型的使用便捷性,由此对比学习的发展进入了较高的阶段(也进入了新的瓶颈)。






