
24年7月进展
第一篇文献
Diffusion Models for Implicit Image Segmentation Ensembles
解决的问题
本文是将扩散模型应用于高层次视觉任务——分割的一次有益尝试,使用了非常简单的训练框架,即可将扩散模型的生成能力应用于医学图像分割任务中。
主要内容
文章其实并没有在框架、算法上有所创新,其使用了非常简单的一种处理方式,将分割模板与待分割的灰度图像直接按通道拼接在一起,然后送入噪声估计器中,直接对模板估计噪声,而图像保持不变。算法上如下式:
方法评价
本文的方法非常聪明,在面对直接加入条件引导或者控制网络等较为复杂的情况下,将模板和条件量(原始图像)按通道拼接后完成条件先验的加入,使用一种成本最低的方式完成了医学图像的分割。在复现中发现,该方法确实简单,但是缺乏条件引导,因此难以收敛。
第二篇文献
SegDiff: image segmentation with diffusion probabilistic models
解决的问题
本文是另一种将扩散模型应用于图像分割领域的尝试,相较于文献1,本文采用的方法更符合传统意义上的控制网络思想,能够解决种类更多、场景更加复杂的分割任务,但是仍然不能超过基于SAM的分割方法。
主要内容
本文将待分割图像的输入经编码器编码为隐变量后,与带噪声的分割模板的编码算术叠加,然后送入噪声估计器的解码器环节完成对模板噪声的估计,整体框架如下图所示:
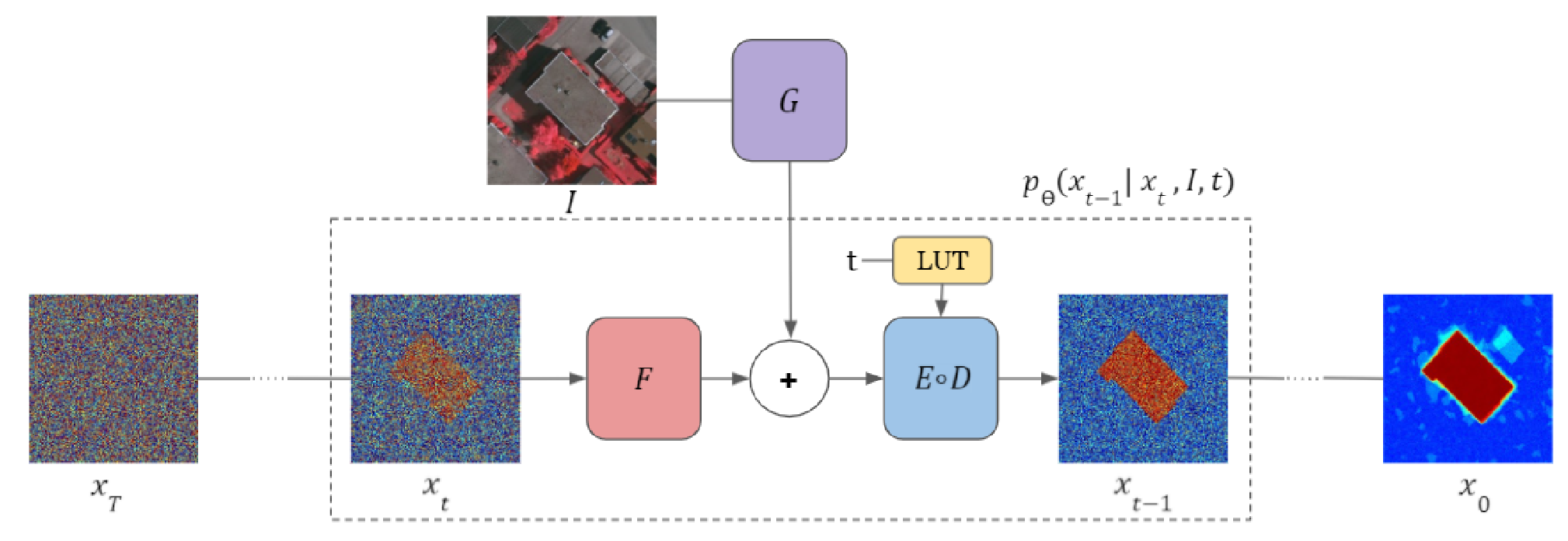
值得注意的是,虽然文章中出现了编码器、解码器等称呼,但是实际上使用的扩散模型仍然是DDPM,而不是LDM,这是因为文章将噪声估计器的UNet网络变成条件UNet,将输入的图像作为条件加入至UNet的另一条分支上,两组输入共同影响最终的噪声估计输出。
文章没有在Loss函数、训练框架上有所创新。
方法评价
本文和文献1都是将分割问题简单地建模为对分割模板的生成问题,应用的损失函数也都是DDPM最原始的二范数损失函数。实践表明,该建模实际上忽略了分割问题的分类要求,仅仅在像素级别上逼近分割模板,结果是并不能取得SOTA的分割效果。
第三篇文献
Generative pretraining from pixels
解决的问题
本文是一篇早期的,关于使用ViT完成视觉自回归任务的论文,解决了如何将Transformer用于图像任务的问题。
主要内容
本文对比了基于GPT模型和BERT模型在token生成上的差异,分别研究了两种模型在图像下游任务上的应用。如下图所示:
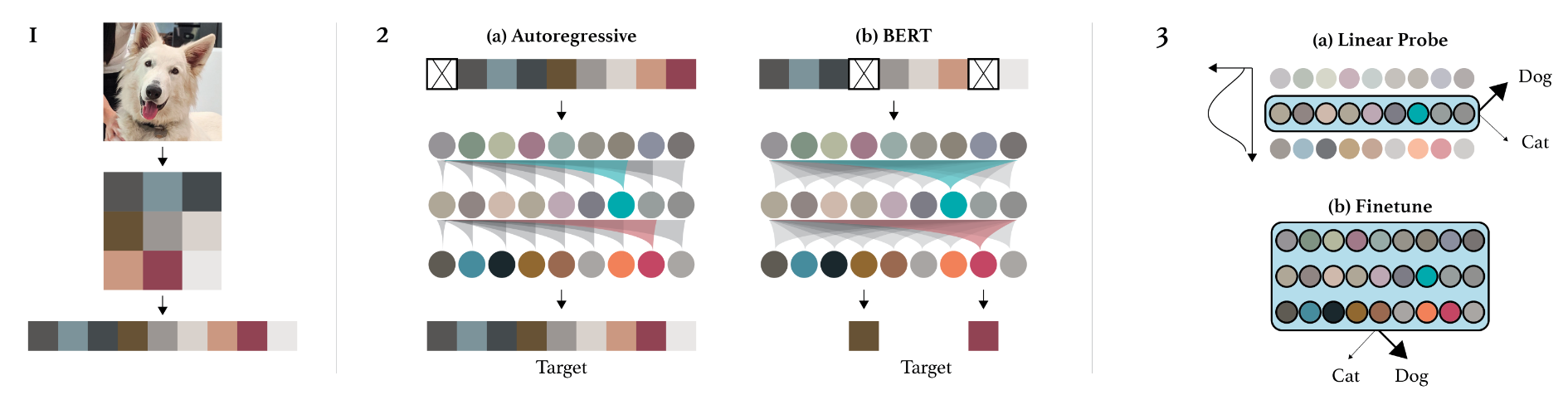
作者经过一百万个迭代次数的预训练后,再经过一百万次的微调,将ViT提取的图像描述特征用于分类任务,并根据线性探测结果验证了ViT的描述提取能力。
方法评价
本文是早期的ViT应用论文,对ViT的探索与把握仍然是有限的。
第四篇文献
An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels
解决的问题
本文是一篇类似于实验报告的文章,研究了如果将图像的单个像素视为独立的token,使用类似GPT的生成方法,能否实现对当前视觉自回归领域的效果的改进。
主要内容
在上下文算力足够支撑的情况下,将单个像素当作token,得到的ViT将变换为更一般形式的生成模型,即PiT,显而易见,PiT有以下好处:
- 全局性增强:PiT不再需要对图像作补丁分块操作,因此直接能够得到任意像素与像素之间的联系;
- 语料库减少:由于token是单个像素,灰度图像的灰度级通常是8级,因此PiT的词汇表最多为256,远远小于ViT的量化码表;
- 泛化能力更强:由于不需要分块,PiT能够处理任意尺寸的图像,甚至是常见的非方形图像。
当然作者也进一步指出,PiT并不是一个切实经济的方案,它需要极高的上下文能力,即使是分辨率较低的256×256图像,也需要个token,远超当前视觉大模型的所能处理的极限,甚至语言大模型的上下文也到不了这么高(最大也才128k)。另外,由于自注意力机制要求对任意两个token都计算一遍,token数量的增长带来的计算量增长也将是难以接受的。
在文章的最后,作者根据PiT在监督、自监督任务上与ViT的表现差异性评价,探讨了ViT不同的分块方式对ViT表现的影响,作者认为影响ViT关键的因素就在于分块方式上,分块不同尤其影响ViT的线性探测能力。
方法评价
本文算是解决我一直以来的一个疑问:为什么不用单个像素作为token使用自注意力机制处理,这就是因为要么是计算量太大,要么是上下文太长,总之都是不现实的。
第五篇文献
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
解决的问题
自回归框架在解决自然语言处理问题上有着巨大的成功,如GPT系列,但是在视觉领域仍然落后基于扩散模型的生成模型,本文将视觉领域的自回归模型作了显著的改进,提出了基于分辨率顺序的视觉自回归模型VAR,使其在多个生成任务的表现上超越了当前最新的扩散模型,甚至超过了DiT。
主要内容
自回归
自回归是时间序列预测方法的术语,即主要解决如何利用前个时间点的数据,预测第个时间点数据,在经济学、统计学和生态学领域有着广泛的应用,也是数学建模的常用套路。关于当前最流行的自回归模型,如果将输入的token看作是数据样本,而将输入的先后视为是时间点的话,那么当前最流行的自然语言处理手段——GPT系列就是应用最为成功的自回归模型之一。对于GPT而言,用于描述该自回归模型的数学公式如下:
其中,是第个token,是token总数,是自回归的滑动窗口大小,是模型参数,训练GPT生成自然语言的过程就是将该似然函数最大化的过程。
视觉自回归
不同于自然语言处理的token序列很“自然”地从左至右从前往后的生成顺序,单独一幅图像,往往包含了极高数量的像素数,因此直接将单个像素视为token是不实用的(虽然它的效果可能会好,如文献4所示,因此最常采用的方式是将图像分块,然后使用量化码表完成词汇表的构建,将每个分块根据其相对位置完成位置编码,组成位置序列,由位置序列输入至ViT中完成自回归输出,如下图所示:
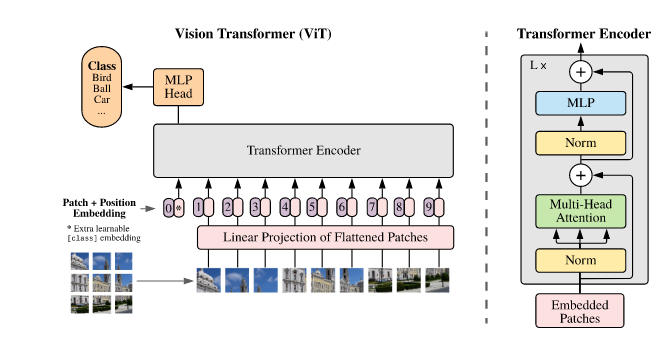
因此生成过程就是已知前一个分块,预测下一个分块,直至所有分块都被预测后,将其按位置拼接为整幅图像,并作后处理完成生成。
本文的改进
基于ViT方式的视觉自回归模型,始终不能战胜基于扩散模型的生成模型。本文探讨后认为最主要的问题是:ViT的生成过程,破坏了自回归模型的顺序性。换言之,由于ViT是将每个分块按相对位置顺序排列的,因此前一个块和后一个块在时间顺序上的联系尚不够紧密(甚至可以说是没有联系),该问题直接限制了当前视觉自回归模型的生成能力。另外,直接对分块作自注意力机制,也将导致的计算量,这也是ViT的一个瓶颈。
本文跳出基于图像局部的自回归机制,改为用更符合人类学习、观察习惯的分辨率金字塔作为回归token,如下图所示:
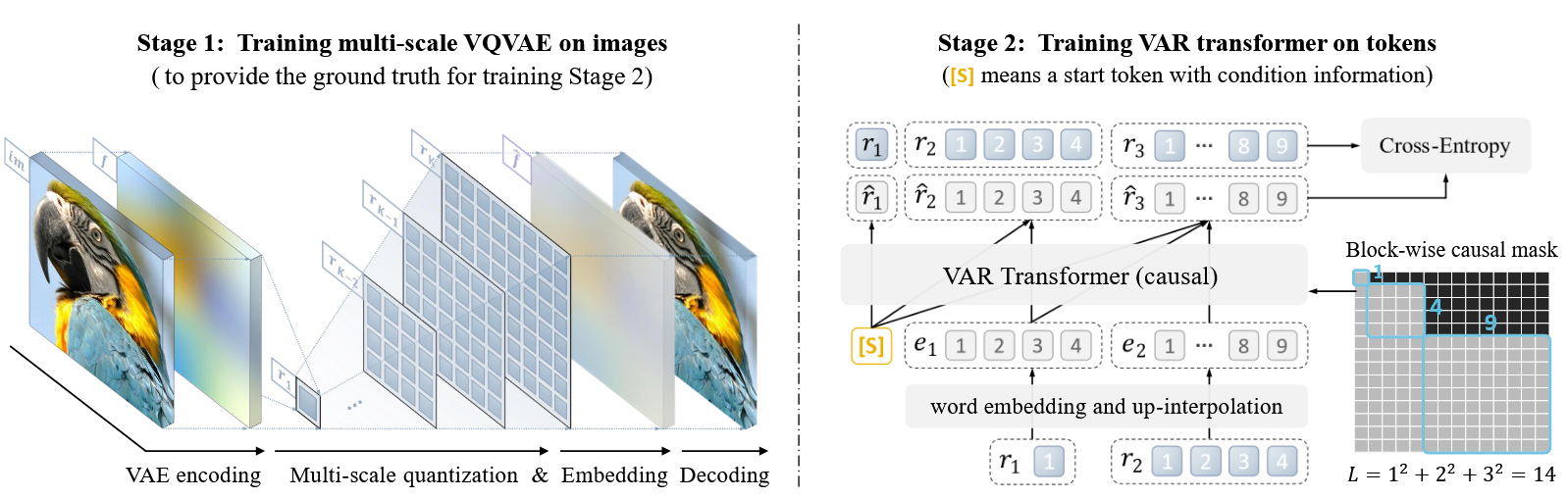
在这种方式下,生成过程就是从最小分辨率开始,逐渐增加分辨率,直至最大分辨率,作者称之为next-scale prediction。作者单独为这种生成方式设计了一个量化自编码器以完成对不同分辨率的token编码,文章的亮点便是体现在对分辨率的编码量化上。该方式自然解决了以往视觉自回归模型中token与token之间的联系问题,同时分辨率token能够保证计算量降低至,这使得VAR的生成速度大大提升,甚至能够逼近GAN的生成速度,远远超过扩散模型。
方法评价
本文开创了新的视觉自回归生成范式,用分辨率作为token完成了对顺序的自然解构,得到了当前最佳的图像生成模型。同时更为重要的是
VAR展现出类似GPT的幂律性质和尺度效应,即,简单地增加模型的规模,模型的泛化性能能够被预测。
而当前的扩散模型也同样遇到了性能瓶颈,即使增加DiT中ViT的规模,也并不能取得相应的性能提升,这是VAR最诱人的一个成果。而如果将尺度更换为三维尺度(加上时间轴),在不改变自回归模型的前提下,即可完成对视频的生成,难怪说VAR是开创了新的研究领域。
第六篇文献
CraterDANet: A Convolutional Neural Network for Small-Scale Crater Detection via Synthetic-to-Real Domain Adaptation
解决的问题
本文讨论了在外星球遥感图像领域的跨域自适应学习能力,






