

祖传代码
前言
本博客只是记录一下从师兄等处继承得到的一些代码及其使用说明。
国产事件相机
SDK及其使用说明:https://github.com/CelePixel。

研究生活
2023/10/8 大作业
国庆节已经过完,最后的长假不情不愿地落下了帷幕。我必须面对看似凶险异常的研究生生活了,曾经许下的承诺每天读一篇文献,其实现在来看也一点没有做到(当然可以给自己找借口说:还没有定方向,但是没有定方向就意味着可以不学习吗?不然也)。在做第一个大作业的时候,我才意识到自己有多么头大,主要遇到了以下的问题:
写报告发现讲事情讲不清楚,抽象能力不够,什么层次该写什么内容?顶层设计需不需要写技术细节?当然是不需要,但是下意识要混一点进去,造成了无处不综述,无处不技术的尴尬局面,以致于写到后面发现没东西可写了。
工程问题和研究问题弄混了,工程问题是理论研究已经很充分了,在理论上证明了问题是可以解决的,才能在工程上去找路径;但是如果理论研究都没有透彻,就要把一个问题转化成工程问题进行研究,可能行得通(像古人那样凭经验和试错),但是大多数情况下是行不通的,切记不要觉得一个问题有趣就把它当作工程问题进行实践,大概率是没有结果的!
2023/10/19 显卡之纠结
从8月底开始陆陆续续一直在关注显卡啊电脑配件这些的价格,看了很久很久,平均每天要在这上面花费一个到两个小时的时间 ...

图像检测模型详解
前言
图像检测领域是一个较大的分支,目前主流的方法是YOLO,但是R-CNN系列也是非常经典的方法,有必要对这两种类型的方法 作深入的了解,才方便 后续的方法 创新。之前一直不理解YOLO模型的Anchor机制的具体含义,直到4月17号才突然明白,原来指的是一种耦合关系。
R-CNN系列
文献
Rich feature hierarchies for accurate object detection and semantic segmentation
Fast R-CNN
解决的问题
检测Detection一词的定义,在文献Regionlets for Generic Object Detection提到过一嘴,本意是从一大堆候选的子区域中,选出来带有物体的区域(也可以是超像素),进一步延伸到了对这个子区域按标签分类,这就是当前深度学习领域检测任务的由来。
这两篇文献,归为同一个类,都是R-CNN检测网络的祖宗之法,是最早提出基于区域的CNN检测方法的文献,其主要解决了CNN不能直接用于检测任务的问题,可谓是开检测领域 深度学习之先河。
主要内容
基于区域的检测方法 ,是这两篇文献 ...

C++学习心得
学习目标
争取熟练掌握C++,达到能够在查看标准库手册、不引入第三方库的情况下独立完成某一个项目的能力,能有python的60%功力就已经足够了,为后续的研究、项目打下基础就好。
学习体会
项目文件夹命名风格:一个文件夹放一个项目,里面有一个include文件夹放头文件,一个src文件夹放源文件,main.cpp文件也需要放在这个文件夹里面。一个项目文件夹内配置一个CMakeLists.txt文件以供Cmake配置。如项目内包括了多个子项目,则另起一个文件夹,将所有子项目放在该文件夹内,并配置一个顶层的CMakeLists.txt文件。
在C语言的变量初始化的基础上,C++增加了更丰富的初始化方法,可以使用默认初始化(按如下语句声明某个类的变量:classname CN),或者使用自定义初始化方法,初始化可以引入参数(类似于python的init函数),初始化方法在类的声明中直接定义,感觉这种语法,更加面向对象,接近于python的风格了。
lambda函数与python一样,没有必要在迭代器的外部单独定义,只需要在使用的时候定义好就行,放在头文件中不合理(因为它是一个对象,头文件中 ...
CUDA编程初体验
前言
真的比较难蚌,谁能想到有朝一日我终于走上了CUDA编程的道路,要不是这个该死的论文非要用什么“弹性可分离卷积”,还真的就不能使用torch直接写出来,必须使用自定义的算子,必须要接触到CUDA编程。
无心插柳柳成荫吧,毕竟,搞深度学习的人不接触一点高性能计算,不懂得一点C++和CUDA编程,说出去给人的感觉也太不专业了,学一点,总归是好的。
CUDA编程基础
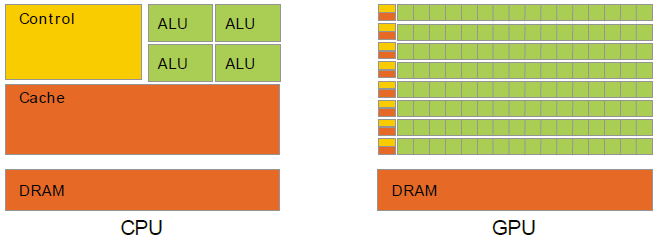
了解CUDA,可参考如下博客,必须要对GPU的硬件架构方式有所了解,对于英伟达的GPU,可使用以下示意图说明:
不同于CPU的冯诺依曼架构,GPU中的控制器与缓存器几乎同时要对应极大数量的低精度算术逻辑单元,这一批算术逻辑单元共享同一个缓存单元,全局共享内存位于DRAM上,DRAM通过PCIE接口与CPU的外接PCIE接口,GPU由于其本身极差的单核 处理性能,其不能单独作为一个计算机系统中央处理单元使用,因此只能作为CPU的一个外部设备device,因此CPU与GPU的关系是协同处理关系。早期的图形处理单元作为外设的普通一员,使用与其他外设共用的南桥接口,受CPU节制;随着图像处理单元的工艺升级和深度学习的应用,现代GP ...
SCADA了解笔记
前言
用于学习过程中的笔记。
部分专业名词
SCADA:Supervisory Control And Data Acquisition,监控与数据采集
DCS:Distributed Control System,分布式控制系统
PLC:Programmable Logic Controller,可编程逻辑控制器
RTU:Remote Terminal Unit,远程终端单元
HMI:Human Machine Interface,人机界面
IED:Intelligent Electronic Device,智能电子设备
MMS:Manufacturing Message Specification,制造信息规范
IT:这个IT不是信息技术,但是是什么还不太清楚
OT:Operational Technology,运营技术(或许?)
TCP:Transmission Control Protocol,传输控制协议
IP:Internet Protocol,网络协议
系统组成
SCADA是指一种介于DCS和PLC之间的控制系统,兼具了PLC的灵活性和DCS的顶层设计。包含了上位机、 ...
Verilog 学习
前言
嵌入式课程和导师的专长都是硬件电路设计,面向应用部署算法,因此有必要了解掌握Verilog语法及其设计思想。
名词解释
VHDL : VHSIC : Very High Speed Integrated Circuit Hardware Description Language.
EDA : Electronic Design Automation
Verilog的五种抽象模型:系统级,算法级,RTL级(Register transfer level)寄存器级,门电路级,开关电路级(深入到三极管内部)
准备工作
使用vscode编译verilog语言并可视化运行
intel自带的quartus软件界面实在过于古老,代码编写跟matlab一样难用,所以我决定使用vscode编写verilog代码并运行一些简单的编译和调试。主要的设置步骤有以下:
安装iverilog编译器,这是一个开源的verilog语言编译器,ubuntu可以直接使用sudo apt install iverilog安装,windows可在网上找官网下载;
安装仿真器gtkwave,这也是开源的示波仿真器,ub ...
mpich 学习
写在前面
从5月8日开始,到现在,已经接近三个月的时间,我的第一段实习生涯即将结束。反思自己的实习经历,我觉得最主要的收获有三点:
最重要的往往是迈出第一步,我从来没有接触过社会化的生产、经营模式,这次实习的企业虽然很小,而且是初创企业,学术氛围浓厚,也给了我较多的眼界,在实习中尝试触摸大学学习和社会生产的脱节处,下一步工作或者学习,都能提供方向上的指引。
第二是克服与生俱来的恐惧心理,至今也还记得实习第一天的时候,来到公司,使用ssh连接服务器、装个python的环境都出了无数个bug,也不敢问近在身边的技术主管和后面的后台管理人员,自己的问题疯狂查CSDN,也始终解决不了,第二天第三天以降,简直如同煎熬,感觉自己什么也不会,一点也不配来这里,压力山大。现在回望,实力是一方面,当时对服务器、对git和linux的使用确实非常不熟悉,另外一个重要的方面,自然是心理压力较大,始终担心自己被别人看不起,不敢问问题,反而限制了自己的进步。
第三才是技术上的一些收获,实习我丝毫没有参与公司的核心业务,主要做的工作是数据集整理和清洗,去重都鲜有涉及。因此指望通过一次实习让自己学到算法上的东西无 ...
图像去雨系列方法汇总
前言
服务于所谓的图像去条纹,真是心都操碎了,到处去查论文看文献,之前一直在图像去噪那里寻寻觅觅冷冷清清,现在总算是找到了方向。
所谓图像去雨,就是广泛意义上的图层分解中,将或者雨滴图层与背景图层**分解开的任务,是图像分解任务中的常见类型,广泛应用于自动驾驶领域的图像预处理。
根据综述文章[1],根据去雨任务的输入模态,可将图像去雨分为两条路线,即基于视频的去雨方法(多针对动态情况下,这种方法在低速自动驾驶上尤为适用)和基于单幅图像的去雨方法(多针对静态或者高速运动下的自动驾驶任务)。本文将主要介绍基于单幅图像的去雨线方法,因为它是非常典型的图像分解任务。进一步,根据去雨任务的技术路线,又可以将去雨方法分为基于模型的去雨方法和基于数据驱动的去雨方法,在数据驱动领域,又可以进一步细分为基于监督训练的方法、基于自监督训练的方法和基于无监督迭代的方法。
本文认为,即使基于监督训练的方法能够在基准测试集上取得较好的结果,但是仍然不足以泛化至真实模型上,基于自监督学习的方法虽然当前泛化能力较差,甚至图像分解的描述提取能力也弱于监督学习,但是其在真实环境中的潜在自适应能力,是真正意义上技术发展的 ...

N2N系列图像去噪方法汇总
前言
这里的图像去噪,更多地指的是带有某些特殊模式的噪声,这种模式大多有特定的物理机理,例如最常见的高斯白噪声和泊松噪声。常规的方法将这些噪声的信息作为先验信息,手工设计处理算法例如BM3D[2]是在深度学习出现之前具有最高的去噪效果,其原理是字典学习(不太理解了)。而本文将主要介绍的是从文献Noise2Noise[1]开始,基于单幅噪声图像,不增加理想图像的自监督网络。
Noise2Noise
本系列的去噪网络前提都是几乎相同的,均来自于文献Noise2Noise[1],基本假设是噪声独立同分布、噪声的期望为零,根据以上两个条件,产生了一系列的衍生网络,首先介绍其数学原理。
数学原理
设理想的、无噪声的图像为x\mathbf{x}x,该图像多称为信号图像或者干净图像,对应的被噪声污染的图像为y\mathbf{y}y,该图像称为退化图像或者噪声图像。理想情况下,如果能够得到对信号图像和噪声图像整个图像空间下的所有分布,则能够以监督学习的方式得到理想的去噪网络f:Rm×n↦Rm×nf:\mathbb{R}^{m\times n}\mapsto\mathbb{R}^{m\times n}f ...

